The realm of cloud computing has revolutionized application development, and at its heart lies serverless computing. This paradigm allows developers to focus on code without managing underlying infrastructure. Two prominent offerings in this space, AWS Lambda and AWS Fargate, offer distinct approaches to achieving serverless functionality. Understanding the nuances between these services is crucial for selecting the optimal compute solution for specific workloads, balancing factors such as cost, control, and operational complexity.
This analysis delves into the core functionalities, operational differences, and ideal use cases of Lambda and Fargate, equipping readers with the knowledge to make informed decisions.
AWS Lambda provides a function-as-a-service (FaaS) model, executing code in response to events, while Fargate offers a serverless container execution environment. Both services aim to eliminate infrastructure management, but they cater to different application architectures and operational preferences. This examination will explore their respective strengths and weaknesses, examining their deployment strategies, resource management capabilities, pricing models, and integration with other AWS services.
Introduction: Defining Serverless Computing
Serverless computing represents a significant paradigm shift in cloud computing, abstracting away the underlying infrastructure management from developers. This allows developers to focus solely on writing and deploying code, without the need to provision, manage, or scale servers. This approach offers significant advantages in terms of operational efficiency, cost optimization, and scalability.Serverless options, such as AWS Lambda and AWS Fargate, provide different approaches to implementing serverless architectures.
Lambda enables developers to execute code in response to events, while Fargate allows them to run containerized applications without managing the underlying infrastructure. These services fit into the broader serverless landscape, providing flexible and scalable solutions for various application workloads.
Core Concept of Serverless Computing and Its Advantages
Serverless computing, at its core, is a cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources. Developers upload code, and the cloud provider handles all aspects of infrastructure management, including server provisioning, scaling, and patching. This model allows developers to focus on application logic without dealing with the complexities of server administration.The advantages of serverless computing are numerous:
- Reduced Operational Overhead: Serverless eliminates the need for server provisioning, management, and maintenance. This frees up developers and operations teams from tasks such as server patching, capacity planning, and scaling.
- Automatic Scaling: Serverless platforms automatically scale resources based on demand. This ensures that applications can handle fluctuating workloads without manual intervention. For example, an e-commerce website built on serverless can automatically scale its backend services during peak shopping seasons, handling thousands of concurrent requests without performance degradation.
- Cost Optimization: Serverless computing typically employs a pay-per-use pricing model. Developers are charged only for the actual compute time and resources consumed by their code. This can result in significant cost savings compared to traditional server-based architectures, especially for applications with intermittent workloads.
- Increased Developer Productivity: By abstracting away infrastructure management, serverless allows developers to focus on writing and deploying code. This accelerates development cycles and improves overall productivity.
- Improved Scalability and Availability: Serverless platforms are designed to be highly scalable and resilient. They automatically distribute workloads across multiple availability zones, ensuring high availability and fault tolerance.
Overview of Lambda and Fargate as Serverless Options
AWS Lambda and AWS Fargate are two prominent serverless offerings within the AWS ecosystem, each providing a distinct approach to serverless computing. Lambda operates on a function-as-a-service (FaaS) model, while Fargate allows for serverless container execution.Lambda is a compute service that lets you run code without provisioning or managing servers. You upload your code as “functions,” and Lambda automatically runs it in response to events, such as changes to data in an Amazon S3 bucket, updates to a database, or HTTP requests.
Lambda functions are stateless and designed to be short-lived, focusing on single-purpose tasks. The execution environment is managed by AWS, handling scaling, security, and monitoring.Fargate, on the other hand, is a serverless compute engine for containers. It allows you to run containerized applications without managing the underlying infrastructure. You define your application’s containers, the required resources (CPU and memory), and Fargate handles the provisioning, scaling, and management of the underlying compute resources.
This simplifies the deployment and operation of containerized applications, allowing developers to focus on application development rather than infrastructure management.
Context of Lambda and Fargate in the Serverless Landscape
Lambda and Fargate, while both serverless, address different aspects of application development and deployment. They can also be used together to create complex serverless architectures. Understanding their respective strengths is key to choosing the right service for a given workload.Lambda is best suited for event-driven applications, backend processing, and tasks that can be broken down into discrete, independent functions. Examples include processing image uploads, transforming data streams, and responding to API requests.Fargate is ideal for containerized applications, microservices, and applications that require more control over the execution environment.
This includes web applications, batch processing jobs, and applications that have dependencies on specific libraries or runtimes.The choice between Lambda and Fargate depends on the specific requirements of the application. Lambda provides a simpler, more streamlined experience for event-driven tasks, while Fargate offers greater flexibility and control for containerized workloads. They can also be combined; for instance, a Lambda function could trigger a Fargate task to process a larger batch of data.The serverless landscape also includes other services that complement Lambda and Fargate, such as API Gateway, which handles API traffic; DynamoDB, a NoSQL database; and S3, an object storage service.
These services can be integrated with Lambda and Fargate to build complete serverless applications.
Lambda
AWS Lambda represents a cornerstone of serverless computing, offering a compute service that executes code in response to events. It abstracts away the underlying infrastructure management, allowing developers to focus solely on their application logic. This event-driven nature is a key differentiator, enabling highly scalable and cost-effective solutions.
Operational Model of AWS Lambda
Lambda operates on a pay-per-use model, meaning you are only charged for the compute time consumed by your function. The service automatically manages the provisioning, scaling, and maintenance of the underlying compute resources. When an event occurs, Lambda triggers the execution of a function. The function code, written in supported languages like Python, Java, Node.js, Go, and others, is executed in a containerized environment.
This environment is isolated from other functions and includes the necessary dependencies. Lambda automatically scales the number of function instances based on the incoming event volume, ensuring optimal performance and availability.
Triggering and Execution of Lambda Functions
Lambda functions are triggered by various event sources, including:
- API Gateway: API Gateway allows you to build, deploy, and manage APIs that can trigger Lambda functions. When an HTTP request is received by API Gateway, it can invoke a Lambda function to process the request.
- Amazon S3: S3 can trigger Lambda functions when objects are created, updated, or deleted in a bucket. This is useful for tasks like image processing, data transformation, or file validation.
- Amazon DynamoDB: DynamoDB can trigger Lambda functions when items are created, updated, or deleted in a table. This enables real-time data processing and event-driven workflows.
- Amazon Kinesis: Kinesis can trigger Lambda functions to process real-time streaming data. This is suitable for tasks like data analytics, log processing, and fraud detection.
- Amazon SNS: SNS can trigger Lambda functions when messages are published to a topic. This facilitates event-driven communication between different parts of an application.
- Amazon CloudWatch Events (now Amazon EventBridge): CloudWatch Events can trigger Lambda functions based on scheduled events or events from other AWS services. This allows for automated tasks and monitoring.
When a trigger event occurs, Lambda does the following:
- Receives the Event: Lambda receives the event from the event source.
- Invokes the Function: Lambda invokes the function associated with the event.
- Executes the Code: The function code is executed in a containerized environment.
- Processes the Event: The function processes the event data.
- Returns a Response (Optional): The function can return a response to the event source or other services.
Lambda’s execution model involves the following:
- Execution Context: Each Lambda function runs within its own execution context. This context includes the function code, environment variables, and temporary storage.
- Concurrency: Lambda can execute multiple function instances concurrently to handle multiple events simultaneously.
- Invocation: An invocation is a single execution of a Lambda function in response to an event.
- Cold Start: A cold start occurs when a new execution environment needs to be created for a function. This can introduce a small delay.
- Warm Start: A warm start occurs when an existing execution environment is reused, resulting in faster invocation times.
Common Use Cases for Lambda
Lambda’s flexibility makes it suitable for a wide range of applications. The following are some common use cases:
- Web Applications: Lambda can power the backend of web applications, handling API requests, processing data, and serving dynamic content.
- Mobile Backends: Lambda can be used to build mobile backends, providing services like user authentication, data storage, and push notifications.
- Data Processing: Lambda can process data from various sources, such as S3 buckets, Kinesis streams, and DynamoDB tables. Tasks include data transformation, filtering, and aggregation.
- Real-time Stream Processing: Lambda can process real-time data streams, enabling applications like fraud detection, anomaly detection, and real-time analytics.
- IoT Applications: Lambda can process data from IoT devices, perform device management, and trigger actions based on sensor data.
- Chatbots: Lambda can be used to build chatbots that respond to user queries, interact with other services, and provide information.
- Image and Video Processing: Lambda can process images and videos, performing tasks like resizing, format conversion, and thumbnail generation.
- Scheduled Tasks: Lambda can execute tasks on a schedule, such as data backups, report generation, and system maintenance.
Fargate: Container-Based Compute
Fargate represents a significant shift in how containerized applications are deployed and managed within cloud environments. It provides a serverless compute engine for containers, eliminating the need for users to manage the underlying infrastructure. This allows developers to focus on building and deploying applications without the operational overhead associated with managing servers, virtual machines, or clusters.
Fargate and Containerized Application Management
Fargate simplifies the deployment and operation of containerized applications by abstracting away the infrastructure management complexities. Users define their container images, the resources required (CPU and memory), and the networking configuration. Fargate then handles the provisioning, scaling, and management of the underlying compute resources. This includes:
- Container Orchestration: Fargate integrates seamlessly with container orchestration services like Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS). It allows users to deploy and manage containers within these orchestrators without needing to provision or manage the underlying EC2 instances.
- Resource Allocation: Fargate dynamically allocates the necessary compute resources based on the defined container requirements. Users specify the CPU and memory needs for each task or pod, and Fargate provisions the appropriate resources.
- Scaling and Availability: Fargate automatically scales the compute resources to match the application’s demand. It also handles the distribution of containers across available resources to ensure high availability and fault tolerance.
- Security Isolation: Fargate provides a secure environment for container execution. Each container runs in its own isolated environment, preventing interference between containers and enhancing security.
Infrastructure Management in Fargate
Fargate’s core strength lies in its abstraction of infrastructure management. Instead of directly interacting with servers or virtual machines, users interact with containers and define their resource requirements. Fargate then handles all aspects of the underlying infrastructure, including:
- Server Provisioning: Fargate automatically provisions and manages the necessary servers to run the containers. This includes selecting the appropriate instance types, configuring the operating system, and ensuring that the servers are properly patched and updated.
- Cluster Management: For services like EKS, Fargate handles the management of the Kubernetes control plane and worker nodes. Users do not need to manage the cluster infrastructure.
- Capacity Management: Fargate dynamically scales the underlying compute capacity based on the application’s demand. It automatically adds or removes servers as needed to ensure that the application has sufficient resources.
- Operating System and Patching: Fargate manages the operating system and patching of the underlying servers. It automatically applies security patches and updates to keep the infrastructure secure.
- Networking: Fargate handles the networking configuration for the containers. It automatically creates and manages the necessary network interfaces, security groups, and load balancers.
Benefits of Fargate Compared to Traditional Container Deployments
Fargate offers several advantages over traditional container deployments, particularly when compared to managing containerized applications on EC2 instances or on-premises infrastructure.
- Reduced Operational Overhead: Fargate eliminates the need to manage servers, clusters, and other infrastructure components. This reduces the operational overhead and allows developers to focus on building and deploying applications.
- Simplified Deployment: Deploying containerized applications with Fargate is simplified. Users only need to define their container images, resource requirements, and networking configuration.
- Improved Scalability: Fargate automatically scales the compute resources to match the application’s demand. This ensures that the application can handle traffic spikes and maintain optimal performance.
- Enhanced Security: Fargate provides a secure environment for container execution. Each container runs in its own isolated environment, enhancing security.
- Cost Optimization: With Fargate, users only pay for the compute resources that their containers consume. This can lead to cost savings compared to managing EC2 instances, where resources may be underutilized.
- Faster Time to Market: By reducing operational overhead and simplifying deployment, Fargate can help developers get their applications to market faster.
For example, a company deploying a web application might choose Fargate over managing EC2 instances. With Fargate, the company can focus on building and deploying the application code, without needing to worry about server provisioning, scaling, or patching. This can lead to a faster time to market and reduced operational costs. Another example is a machine learning company that wants to deploy containerized models for inference.
Fargate allows them to deploy these models without needing to manage the underlying infrastructure, simplifying the deployment process and allowing them to scale the inference service as needed.
Operational Differences
The operational characteristics of AWS Lambda and Fargate diverge significantly, particularly in deployment and scaling. These differences influence the operational overhead, cost considerations, and suitability for various application architectures. Understanding these distinctions is crucial for making informed decisions about which service best aligns with specific project requirements.
Deployment Process Comparison
The deployment process for Lambda and Fargate exhibits distinct approaches. These differences stem from their underlying architectures and the level of control offered to the user.For AWS Lambda:
- Lambda functions are deployed as code packages, typically in the form of a ZIP archive containing the function code and its dependencies.
- Deployment involves uploading this package to AWS. This can be done through the AWS Management Console, the AWS CLI, or using infrastructure-as-code tools like AWS CloudFormation or Terraform.
- AWS handles the underlying infrastructure management, including server provisioning, patching, and scaling.
- Deployment typically involves setting configuration parameters such as memory allocation, timeout duration, and environment variables.
For AWS Fargate:
- Fargate deployments involve container images, built using Docker or other containerization technologies.
- The container image, containing the application code and all its dependencies, is stored in a container registry, such as Amazon ECR (Elastic Container Registry) or Docker Hub.
- Deployment involves defining a task definition, which specifies the container image, resource allocation (CPU and memory), networking configuration, and other parameters.
- This task definition is then used to launch container instances (tasks) within an ECS (Elastic Container Service) cluster or EKS (Elastic Kubernetes Service) cluster managed by Fargate.
- The user manages the container image and configuration, while Fargate handles the underlying infrastructure.
Scaling Mechanisms Analysis
Scaling in response to demand is a critical aspect of serverless and containerized applications. Both Lambda and Fargate employ different mechanisms to handle scaling, impacting their responsiveness and cost efficiency.For AWS Lambda:
- Lambda automatically scales in response to the number of incoming requests.
- When a request arrives, Lambda attempts to find an existing execution environment (container) to process the request. If no such environment is available, it creates a new one, known as a function instance.
- Lambda scales by provisioning more function instances concurrently.
- The scaling is determined by a concurrency limit, which can be adjusted, and the available resources in the AWS region.
- Lambda’s scaling is typically very rapid, often scaling up or down within milliseconds.
For AWS Fargate:
- Fargate scales by launching new container instances (tasks) in response to increased demand.
- Scaling is often managed through the use of a service scheduler, such as the ECS service scheduler or the Kubernetes deployment controller.
- The scheduler monitors the desired number of running tasks and automatically adjusts this number based on metrics such as CPU utilization, memory utilization, or custom application metrics.
- Scaling can be triggered by CloudWatch alarms, which monitor these metrics and trigger scaling events when thresholds are met.
- Scaling in Fargate is generally slower than Lambda, as it involves provisioning new container instances, which takes longer than Lambda’s instance creation process.
Scaling Characteristics Comparison Table
The following table compares the scaling characteristics of AWS Lambda and AWS Fargate:
| Characteristic | AWS Lambda | AWS Fargate | Notes |
|---|---|---|---|
| Scaling Trigger | Automatic based on incoming requests | Metric-based (CPU, memory, custom metrics) | Lambda scales automatically, while Fargate requires explicit configuration of scaling policies. |
| Scaling Speed | Very Fast (milliseconds) | Slower (seconds to minutes) | Lambda scales almost instantaneously, while Fargate scaling depends on container provisioning. |
| Concurrency Control | Concurrency limits (adjustable) | Task limits and resource allocation | Lambda uses concurrency limits to control the number of concurrent function invocations, while Fargate uses task definitions to manage resource allocation. |
| Cost Implications | Pay-per-use, billed per invocation and execution time | Pay-per-use, billed per vCPU and memory allocation, for the duration of the task run | Lambda is often more cost-effective for intermittent workloads, while Fargate can be more cost-effective for sustained workloads with consistent resource needs. |
Operational Differences
The operational characteristics of AWS Lambda and AWS Fargate diverge significantly, particularly in how they handle resource management. Understanding these differences is crucial for selecting the appropriate service based on application requirements and operational preferences. The core of this distinction lies in the level of control and abstraction each service provides over the underlying infrastructure.
Resource Management in Lambda
AWS Lambda abstracts away the underlying compute infrastructure entirely. Developers interact with Lambda functions, not with servers or virtual machines. Lambda automatically manages compute resources, scaling them up or down based on the incoming event load. This dynamic allocation is a key feature of Lambda’s serverless architecture.Lambda’s resource management operates on the following principles:
- CPU Allocation: Lambda allocates CPU power proportionally to the amount of memory configured for the function. More memory means more CPU. There is no direct control over CPU cores; the system determines the number of vCPUs available based on memory settings.
- Memory Allocation: Memory is a critical configuration parameter for a Lambda function. Developers specify the memory allocation in MB, and Lambda automatically allocates the corresponding CPU and other resources. This simplified model removes the need for manual resource provisioning.
- Resource Scaling: Lambda automatically scales the number of function instances based on the number of incoming events. When an event triggers a function, Lambda provisions an instance of the function. As the event load increases, Lambda scales out by creating additional instances to handle the increased demand.
- Execution Environment: Each Lambda function runs within an isolated execution environment. This environment includes the operating system, runtime environment, and any configured dependencies. The environment is ephemeral; it is created when the function is invoked and destroyed when the function completes.
Resource Allocation in Fargate
AWS Fargate, on the other hand, provides a container-based compute environment where users define the resource allocation for each container task. This offers more control over the compute resources. Developers specify the CPU and memory requirements for each container, allowing for fine-grained resource optimization.Fargate’s resource management features include:
- CPU and Memory Specification: When defining a Fargate task, users explicitly specify the CPU (in vCPUs) and memory (in GB) required by the container. This allows for precise resource allocation based on the application’s needs. Different task definitions can be used to specify varying resource requirements.
- Task Execution: Fargate runs containers within isolated environments, providing a dedicated compute infrastructure for each task. Each task receives the resources specified in the task definition.
- Scaling with ECS/EKS: Fargate tasks are typically managed using Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS). These orchestration services handle the scaling of tasks based on defined scaling policies or manual intervention. Scaling can be automated using metrics like CPU utilization or request queue length.
- Resource Limits: Fargate allows users to set resource limits to prevent tasks from consuming excessive resources. This is critical for controlling costs and maintaining application performance.
Differences in Resource Provisioning and Control
The primary difference lies in the level of control and abstraction. Lambda abstracts away almost all infrastructure management, while Fargate provides more control over resource allocation. This impacts the level of effort required for configuration, monitoring, and optimization.The following table summarizes the key differences:
| Feature | Lambda | Fargate |
|---|---|---|
| CPU Allocation | Proportional to memory allocation | User-defined (vCPUs) |
| Memory Allocation | User-defined (MB) | User-defined (GB) |
| Resource Control | Limited; automated scaling | More granular control over resources |
| Infrastructure Management | Abstracted; no server management | User defines resources for containers |
| Scaling | Automatic based on event load | Managed via ECS/EKS, can be automated |
For instance, consider a scenario where a machine learning model is deployed. Lambda’s automatic scaling could be advantageous for sporadic, event-driven inference tasks, handling fluctuating request volumes without manual intervention. However, if the model requires a specific amount of CPU and GPU for consistent performance, Fargate, in conjunction with ECS, provides the necessary control over resource allocation and isolation, potentially resulting in more predictable performance.
This is especially relevant when dealing with computationally intensive tasks or tasks with specific hardware requirements, where the flexibility of defining resource allocation is paramount.
Programming Model and Application Structure
The programming model and application structure significantly differ between AWS Lambda and Fargate, reflecting their fundamental architectural distinctions. Understanding these differences is crucial for selecting the appropriate service for a given workload and for optimizing application design. Lambda’s event-driven, function-based approach contrasts sharply with Fargate’s container-centric model, influencing how developers build, deploy, and manage their applications.
Programming Model for Lambda
Lambda’s programming model is centered around functions. These functions are triggered by events from various AWS services or external sources. Developers write code that executes in response to these events, with Lambda managing the underlying infrastructure. This model promotes a serverless approach, where developers focus on code rather than server management.The programming model for Lambda can be summarized by the following:
- Event-Driven Execution: Lambda functions are triggered by events. These events can originate from a wide range of sources, including API Gateway requests, S3 object uploads, DynamoDB updates, and scheduled events. The event data is passed to the function as input, allowing the function to process the event. For instance, when an image is uploaded to an S3 bucket, a Lambda function can be triggered to generate thumbnails.
- Stateless Functions: Lambda functions are designed to be stateless. Each invocation is isolated, and there is no persistent state maintained between invocations. If state is required, it must be stored externally, such as in a database (e.g., DynamoDB, RDS) or object storage (e.g., S3).
- Function Code: Developers write functions in supported programming languages, including Python, Node.js, Java, Go, and C#. The code is packaged and uploaded to Lambda. The function code is executed in a managed runtime environment provided by Lambda.
- Concurrency and Scaling: Lambda automatically scales by launching new function instances to handle concurrent requests. This scaling is based on the volume of events. There are limits on the number of concurrent executions, but these can be adjusted.
- Resource Allocation: When creating a Lambda function, developers specify the memory allocation for the function. The CPU and other resources are automatically allocated based on the memory setting.
Architectural Considerations for Lambda Applications
Building applications with Lambda necessitates careful architectural considerations to leverage its serverless benefits while addressing potential challenges. Key aspects to consider are:
- Event Source Integration: Effectively integrating Lambda functions with event sources is critical. Developers must understand the event data structure and how to process it within the function. For example, when processing a message from an SQS queue, the Lambda function must correctly parse the message payload.
- Stateless Design: As mentioned previously, the stateless nature of Lambda requires careful consideration of state management. External services, such as databases or caching layers, must be used to store and retrieve state information. For example, session management in a web application would typically involve storing session data in a database or caching system.
- Idempotency: Because of the possibility of retries and concurrent executions, Lambda functions should be designed to be idempotent, meaning that executing the same function multiple times with the same input has the same effect as executing it once. This is crucial to avoid unintended side effects.
- Error Handling and Monitoring: Implementing robust error handling and monitoring is essential. Lambda functions should include error handling mechanisms to gracefully handle exceptions. CloudWatch Logs and CloudWatch Metrics are used to monitor function performance, identify errors, and troubleshoot issues.
- Orchestration and Workflow Management: For complex workflows, Lambda functions can be orchestrated using services like AWS Step Functions. This allows developers to create stateful workflows by chaining multiple Lambda functions together.
- Security: Securing Lambda functions involves managing IAM roles and permissions. The IAM role assigned to a Lambda function defines its access to other AWS resources. It’s essential to adhere to the principle of least privilege, granting functions only the necessary permissions.
Application Structure for Fargate
Fargate applications are containerized. The application structure revolves around defining container images, orchestrating containers, and managing their lifecycle. The following Artikels a typical Fargate application structure:
- Container Images: Applications are packaged as container images, using technologies like Docker. These images contain the application code, runtime environment, and dependencies.
- Task Definitions: Task definitions define the containers to run, the resources allocated to them (CPU and memory), and other configurations, such as networking and environment variables.
- Container Orchestration (e.g., ECS): Fargate is integrated with container orchestration services, such as Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Service (EKS). These services manage the lifecycle of the containers, including starting, stopping, scaling, and health monitoring.
- Networking: Fargate tasks run within a virtual private cloud (VPC). The application’s network configuration, including security groups and subnets, is defined within the task definition.
- Service Discovery: For applications with multiple containers or services, service discovery mechanisms are used to enable communication between them. This could be through ECS Service Discovery or other service discovery tools.
- Load Balancing: Load balancers, such as Application Load Balancers (ALB) or Network Load Balancers (NLB), are often used to distribute traffic across multiple Fargate tasks.
For example, consider a web application deployed on Fargate. The application might be structured as follows:
- Frontend Container: A container running the web application’s frontend code (e.g., React, Angular).
- Backend Container: A container running the web application’s backend code (e.g., Python/Flask, Node.js/Express).
- Database Container (optional): A container running a database server (e.g., PostgreSQL, MySQL) or a connection to an external database service.
- Load Balancer: An Application Load Balancer (ALB) distributes incoming HTTP/HTTPS traffic across the frontend containers.
- Task Definition: Defines the frontend, backend, and database containers, their resource allocation, and networking configurations.
- ECS Service: Manages the deployment and scaling of the containers based on the task definition.
Pricing Models: Cost Considerations
Understanding the pricing models of AWS Lambda and Fargate is crucial for making informed decisions about workload deployment and optimizing cloud spending. These models differ significantly, reflecting the underlying infrastructure and operational approaches. This section will delve into the specifics of each service’s pricing structure and provide a comparative analysis to aid in selecting the most cost-effective solution.
Lambda Pricing Model
Lambda’s pricing is primarily based on the duration of the function execution and the number of invocations. Other factors, such as memory allocation and the use of provisioned concurrency, also influence the final cost.
- Invocation Requests: This represents the number of times your Lambda function is executed. AWS charges a small fee per request. The exact price varies by region.
- Duration: This is the time your function runs, measured in milliseconds. The price is determined by the function’s memory allocation and the duration of the execution. The cost per GB-second varies. For example, as of October 2024, in the US East (N. Virginia) region, the price is approximately $0.00001667 per GB-second.
- Memory Allocation: The amount of memory allocated to your function directly impacts the cost. Higher memory allocation allows for more CPU and network resources, but it also increases the cost per GB-second. You can configure memory from 128MB to 10GB.
- Provisioned Concurrency: This feature allows you to pre-provision a specific number of execution environments for your function. While this improves latency by reducing cold starts, it also incurs a cost for the provisioned capacity, whether the function is actively invoked or not. This is charged on an hourly basis.
- Free Tier: AWS provides a free tier for Lambda, offering a certain number of free invocations and compute time each month. This allows for cost-free experimentation and for handling small-scale workloads.
Fargate Pricing Model
Fargate pricing is based on the vCPU and memory resources consumed by your containerized applications, as well as the duration of their execution. Unlike Lambda, Fargate charges for resource allocation regardless of actual utilization.
- vCPU and Memory: You specify the vCPU and memory requirements for your container tasks. The cost is calculated based on the requested vCPU and memory, even if the container is not fully utilizing those resources.
- Duration: The execution time of your container tasks, from the time the container starts running until it terminates, is a key factor in cost calculation.
- Operating System: The operating system of the container also affects the cost, with certain operating systems having slightly different pricing models.
- Region: Pricing varies by AWS region.
- Spot Instances (Optional): Fargate also supports spot instances, which can significantly reduce costs for fault-tolerant workloads. Spot instances utilize spare compute capacity in the AWS cloud, but they can be interrupted if AWS needs the capacity back. The cost savings are often substantial.
Comparing Lambda and Fargate Pricing
The optimal choice between Lambda and Fargate depends heavily on the specific workload characteristics. Lambda is often more cost-effective for event-driven, intermittent workloads where execution time is short and the number of invocations is moderate. Fargate, on the other hand, might be more suitable for long-running, stateful applications or workloads that require consistent resource allocation.
Example: Consider two scenarios. Scenario 1 involves processing image thumbnails triggered by object uploads to an S3 bucket (Lambda). Scenario 2 involves running a web application with predictable traffic patterns (Fargate). For Scenario 1, Lambda is likely more cost-effective because the function is invoked infrequently and executes quickly. For Scenario 2, Fargate might be preferable because the application requires consistent uptime and resource availability, and the costs can be predicted more accurately based on resource allocation and expected duration.
If traffic is unpredictable, and auto-scaling is implemented in Fargate, Lambda could become more cost-effective for short bursts of traffic.
Use Cases: Best-Fit Scenarios
The choice between AWS Lambda and Fargate is fundamentally driven by the specific requirements of an application and its operational context. Understanding the strengths and weaknesses of each service in various scenarios is crucial for optimal resource allocation, cost management, and overall system performance. This section will delve into the ideal use cases for each service, highlighting scenarios where one excels over the other, and providing practical examples to illustrate these differences.
Ideal Use Cases for AWS Lambda
Lambda’s serverless nature makes it exceptionally well-suited for event-driven architectures and workloads characterized by intermittent or unpredictable traffic patterns. Its pay-per-use pricing model and automatic scaling capabilities contribute to cost-effectiveness and operational simplicity in these contexts.
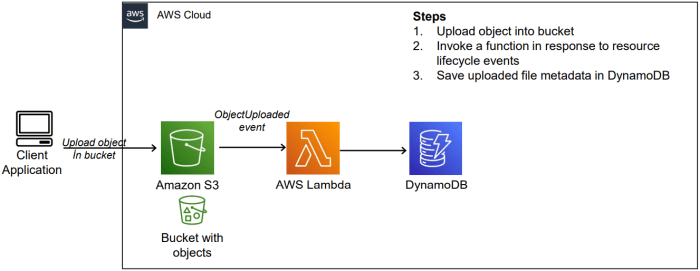
- Event-Driven Processing: Lambda is a natural fit for processing events from various AWS services, such as S3 object uploads, DynamoDB stream changes, and API Gateway requests. For example, an image resizing service could be triggered by an S3 upload event, with Lambda automatically resizing the image and storing the result. This eliminates the need to manage servers and scales seamlessly with the number of uploaded images.
- Web Applications and APIs: Lambda functions can be used as the backend for web applications and APIs, often in conjunction with API Gateway. This allows developers to build scalable and cost-effective APIs without managing any infrastructure. A common example is a simple REST API for a to-do list application, where each API endpoint triggers a Lambda function to handle requests.
- Data Processing and Transformation: Lambda can be used to process and transform data in response to events or on a scheduled basis. This includes tasks like data validation, aggregation, and enrichment. For example, a Lambda function could be triggered by a message in an SQS queue, processing the message and updating a database.
- Scheduled Tasks: Using CloudWatch Events (now EventBridge), Lambda functions can be scheduled to run at specific intervals. This is useful for tasks like generating reports, performing backups, and running maintenance scripts. For example, a Lambda function could be scheduled to archive old database records every night.
- Mobile Backends: Lambda can provide backend functionality for mobile applications, handling tasks such as user authentication, data storage, and push notifications. This allows mobile developers to focus on the client-side experience without managing server infrastructure.
Appropriate Scenarios for Deploying Applications with Fargate
Fargate is best suited for containerized applications that require more control over the underlying infrastructure, have long-running processes, or need to leverage existing container images. Its container-based approach allows for greater flexibility and portability compared to Lambda, particularly for applications with complex dependencies or specific resource requirements.
- Long-Running Processes: Fargate is ideal for applications that need to run continuously, such as web servers, microservices, and background processing tasks. Unlike Lambda, which has a maximum execution time, Fargate can run containers for extended periods.
- Containerized Applications: If an application is already containerized using Docker, Fargate provides a straightforward way to deploy and manage it without managing the underlying EC2 instances. This simplifies the deployment process and ensures consistency across different environments. For instance, a containerized application built with Python, utilizing the Flask framework, can be deployed using Fargate.
- Microservices Architectures: Fargate is well-suited for deploying and scaling microservices. Each microservice can be packaged as a container and deployed independently, allowing for flexible scaling and independent updates.
- Applications with Complex Dependencies: Applications with complex dependencies, such as those requiring specific libraries or runtimes, can benefit from Fargate. The containerized environment allows developers to control the entire software stack and ensure that all dependencies are met.
- Stateful Applications: While Lambda is generally stateless, Fargate can be used to run stateful applications, such as databases and caching servers, although it requires careful consideration of data persistence and storage. For example, a Redis cache can be deployed on Fargate, storing session data for a web application.
Scenarios Where One Service is More Advantageous Than the Other
The decision between Lambda and Fargate often hinges on the specific characteristics of the workload, particularly in terms of execution time, resource requirements, and operational complexity.
- Short-Lived Tasks vs. Long-Running Processes: Lambda excels at short-lived, event-driven tasks that can be executed quickly and efficiently. Fargate is more appropriate for long-running processes that require continuous operation or have longer execution times. For instance, a simple image thumbnail generation would be suitable for Lambda, while a video transcoding service might be better suited for Fargate.
- Event-Driven vs. Orchestrated Workloads: Lambda is naturally integrated with event-driven architectures, where functions are triggered by events from other services. Fargate is better suited for orchestrated workloads, where containers are managed and deployed as part of a larger application or microservices architecture.
- Stateless vs. Stateful Applications: Lambda is inherently stateless, making it suitable for tasks that do not require persistent storage or complex state management. Fargate can be used for stateful applications, although it requires careful planning for data persistence and storage.
- Cost Considerations: Lambda’s pay-per-use pricing model can be highly cost-effective for workloads with intermittent or unpredictable traffic patterns. Fargate’s pricing is based on the resources consumed, making it more suitable for applications with consistent workloads.
- Control and Customization: Fargate provides greater control over the underlying infrastructure and allows for more customization of the container environment. Lambda offers a more managed experience, simplifying operations but limiting control over the underlying resources.
Integration with Other AWS Services
Effective integration with other AWS services is crucial for both Lambda and Fargate, enabling them to function as part of a larger, more complex application architecture. This integration facilitates data flow, event triggering, and communication between various components, enhancing the overall functionality and scalability of serverless and containerized applications.
Lambda Integration with AWS Services
Lambda’s serverless nature allows for seamless integration with a wide array of AWS services, leveraging event-driven architectures and simplifying application development. These integrations are typically accomplished through triggers, input streams, and API calls, enabling Lambda functions to react to events, process data, and interact with other services.
- API Gateway: Lambda functions can be triggered by API Gateway, allowing them to serve as backends for REST APIs, WebSockets, and other HTTP-based services. This enables the creation of scalable and cost-effective APIs without the need to manage servers. For example, a user request through an API Gateway endpoint can trigger a Lambda function to retrieve data from a database or perform a calculation.
- S3 (Simple Storage Service): Lambda functions can be triggered by events in S3, such as object creation, deletion, or modification. This allows for automated processing of files stored in S3, such as image resizing, video transcoding, or data transformation. For instance, uploading an image to an S3 bucket can automatically trigger a Lambda function to generate thumbnails.
- DynamoDB: Lambda functions can be triggered by changes in DynamoDB tables, such as item creation, update, or deletion. This facilitates real-time data processing, such as sending notifications or updating related data. A common example is triggering a Lambda function to send a notification when a new order is added to a DynamoDB table.
- SNS (Simple Notification Service) and SQS (Simple Queue Service): Lambda functions can subscribe to SNS topics or SQS queues to receive messages. This enables asynchronous processing of events and decoupling of application components. SNS is used for fan-out scenarios, where the same message is delivered to multiple subscribers (e.g., sending notifications to multiple users). SQS is used for queuing messages for later processing by Lambda functions, useful for handling peak loads and ensuring message delivery.
- Kinesis: Lambda functions can process real-time streaming data from Kinesis data streams. This enables applications to perform real-time analytics, data transformations, and other operations on streaming data. For example, analyzing clickstream data from a website in real-time.
Fargate Integration with AWS Services
Fargate, being a container-based compute service, integrates primarily through its containerized applications’ ability to interact with other AWS services. This integration often involves configuring network access, managing container image repositories, and using SDKs to communicate with other AWS services. The containerized applications running on Fargate have access to AWS resources through various mechanisms, allowing for flexible and scalable application architectures.
- ECS (Elastic Container Service) and ECR (Elastic Container Registry): Fargate is tightly integrated with ECS, which is used to manage and orchestrate containerized applications. ECS allows you to define tasks that run on Fargate, specifying the container images to use, resource requirements, and other configuration settings. ECR is used to store and manage container images, allowing Fargate tasks to pull the required images.
- VPC (Virtual Private Cloud): Fargate tasks run within a VPC, allowing them to access other resources within the VPC, such as databases, caches, and other services. This also allows you to control the network access of your Fargate tasks.
- Load Balancers (ALB, NLB): Fargate tasks can be integrated with Application Load Balancers (ALB) and Network Load Balancers (NLB) to distribute traffic across multiple container instances. This enables high availability and scalability for applications running on Fargate.
- CloudWatch: Fargate integrates with CloudWatch for monitoring and logging. Metrics such as CPU utilization, memory usage, and network traffic can be monitored, and logs from the containerized applications can be sent to CloudWatch Logs for analysis.
- IAM (Identity and Access Management): Fargate tasks can be configured with IAM roles to grant them access to other AWS services, such as S3, DynamoDB, and other services. This enables the containerized applications to interact with these services securely.
Common Integrations Matrix
The following table provides a comparative overview of common integrations for both Lambda and Fargate, highlighting the primary services and their typical uses.
| Service | Lambda Integration | Fargate Integration | Description |
|---|---|---|---|
| API Gateway | Triggers Lambda functions to serve as API backends. | Applications running on Fargate can be exposed via API Gateway, utilizing Fargate’s scalability. | Enables building scalable APIs with serverless or containerized backends. |
| S3 | Lambda functions can be triggered by S3 events (e.g., object creation). | Fargate applications can access and process data stored in S3 using AWS SDKs. | Facilitates automated data processing and storage management. |
| DynamoDB | Lambda functions can be triggered by DynamoDB table changes. | Fargate applications can access and manipulate DynamoDB data using AWS SDKs. | Enables real-time data processing and interaction with NoSQL databases. |
| SNS/SQS | Lambda functions can subscribe to SNS topics and SQS queues for asynchronous processing. | Fargate applications can publish messages to SNS topics and consume messages from SQS queues. | Supports asynchronous communication and decoupling of application components. |
| Kinesis | Lambda functions can process real-time streaming data from Kinesis streams. | Fargate applications can access and process real-time data from Kinesis streams using AWS SDKs. | Enables real-time data analytics and processing of streaming data. |
| ECS/ECR | Not directly applicable. | Fargate is managed via ECS, utilizing ECR for container image storage. | ECS orchestrates Fargate tasks, and ECR stores the necessary container images. |
| CloudWatch | Lambda functions automatically send logs and metrics to CloudWatch. | Fargate applications send logs and metrics to CloudWatch for monitoring and logging. | Provides monitoring, logging, and alerting capabilities for applications. |
| IAM | Lambda functions are assigned IAM roles for accessing other AWS services. | Fargate tasks are assigned IAM roles for secure access to other AWS services. | Enables secure access to other AWS resources and services. |
Security Considerations

Security is a paramount concern in any cloud-based environment, and both AWS Lambda and Fargate offer distinct approaches to securing your applications. Understanding these differences and implementing best practices is crucial for protecting your workloads.
Lambda Security Model: IAM Roles and Permissions
The security model for AWS Lambda functions primarily revolves around AWS Identity and Access Management (IAM) roles and permissions. These roles define what a Lambda function is authorized to do.
- IAM Roles: Each Lambda function assumes an IAM role when it executes. This role grants the function the necessary permissions to access other AWS resources, such as S3 buckets, DynamoDB tables, or other services. The role is configured during function creation or updates.
- Permissions Granularity: IAM policies, which are attached to the IAM role, specify the exact actions a Lambda function is allowed to perform. These policies utilize the principle of least privilege, granting only the necessary permissions to minimize the potential impact of a security breach. For example, a Lambda function that reads from an S3 bucket should only have the `s3:GetObject` permission for that specific bucket.
- Execution Context: Lambda functions execute in a secure, isolated environment. AWS manages the underlying infrastructure, including patching and security updates. Functions do not have direct access to the underlying operating system or network configuration, which reduces the attack surface.
- Resource-Based Policies: Besides IAM roles, resource-based policies can be used to grant permissions to Lambda functions. For example, an S3 bucket can have a policy that allows a specific Lambda function to read objects from it. This can be useful when managing access across different AWS accounts.
- Security Groups (Limited): While Lambda functions don’t directly use security groups in the same way as EC2 instances, you can configure VPC settings for your functions. This allows the function to access resources within a VPC, and then, security groups can be used to control inbound and outbound traffic for those VPC resources.
Fargate Deployment Security: Container Security
Fargate deployments provide a different approach to security, primarily focusing on container security.
- Container Isolation: Fargate isolates each container by using a hardened operating system and kernel. This isolation prevents containers from interfering with each other and limits the impact of a compromised container.
- Image Security: The security of a Fargate deployment is heavily dependent on the container images used. Best practices include using a trusted base image, regularly scanning images for vulnerabilities, and patching any identified issues. Container image scanning tools can identify known vulnerabilities in the image layers.
- IAM Roles for Tasks: Similar to Lambda, Fargate tasks also use IAM roles to grant them permissions to access other AWS resources. The IAM role is associated with the task definition.
- Network Security: Fargate tasks run within a VPC, and security groups can be used to control inbound and outbound traffic to and from the tasks. Network ACLs can provide an additional layer of network security.
- Secrets Management: AWS Secrets Manager or AWS Systems Manager Parameter Store can be used to securely store and manage sensitive information, such as database credentials or API keys. These secrets can be accessed by the containers at runtime.
Security Best Practices for Both Services
Implementing security best practices is crucial for both Lambda and Fargate deployments.
- Principle of Least Privilege: Grant only the necessary permissions to your Lambda functions and Fargate tasks. This minimizes the potential impact of a security breach.
- Regular Auditing: Regularly audit your IAM roles and policies to ensure they are configured correctly and follow the principle of least privilege. AWS CloudTrail can be used to monitor API calls and identify any suspicious activity.
- Vulnerability Scanning: Regularly scan your container images for vulnerabilities. Tools like Amazon ECR Image Scan can help identify and remediate security issues. For Lambda functions, regularly review and update dependencies to patch security vulnerabilities.
- Secrets Management: Never hardcode sensitive information, such as passwords or API keys, directly into your code. Use AWS Secrets Manager or AWS Systems Manager Parameter Store to securely store and manage these secrets.
- Network Security: Use security groups and network ACLs to control network traffic to and from your resources. Configure VPC settings appropriately to isolate your resources.
- Logging and Monitoring: Implement comprehensive logging and monitoring to detect and respond to security incidents. AWS CloudWatch can be used to collect and analyze logs and metrics. Configure alerts to notify you of any unusual activity.
- Encryption: Encrypt data at rest and in transit. Use AWS KMS for key management and encryption of sensitive data stored in S3 buckets or other services. Utilize HTTPS for secure communication.
- Regular Updates: Keep your Lambda functions’ dependencies and your container images up-to-date to address any security vulnerabilities. Apply security patches promptly.
- Multi-Factor Authentication (MFA): Enable MFA for all IAM users to protect against unauthorized access to your AWS account.
Monitoring and Logging: Operational Insights
Effective monitoring and logging are critical for maintaining the health, performance, and security of any cloud-based application. They provide crucial insights into application behavior, enabling proactive identification and resolution of issues, performance optimization, and security threat detection. This section delves into the specific monitoring and logging capabilities offered by AWS Lambda and Fargate, highlighting their respective strengths and limitations.
Monitoring Lambda Function Performance and Logs
Lambda functions are intrinsically linked to AWS CloudWatch for monitoring and logging. CloudWatch provides a centralized platform for collecting, analyzing, and visualizing metrics and logs related to Lambda function executions.
- Metrics Collection: CloudWatch automatically collects several key metrics for each Lambda function. These include:
- Invocations: The number of times the function was executed.
- Errors: The number of function invocations that resulted in errors.
- Throttles: The number of times the function was throttled due to exceeding concurrency limits.
- Duration: The amount of time the function took to execute.
- ConcurrentExecutions: The number of function instances running concurrently.
- IteratorAge: (for event source mappings) The age of the last record processed.
These metrics are automatically available in the CloudWatch console and can be used to create dashboards, set alarms, and track function performance over time.
- Log Aggregation: Lambda functions automatically send logs to CloudWatch Logs. These logs contain detailed information about each function invocation, including:
- Execution start and end times.
- Function input and output.
- Any log statements written by the function code.
- Error messages and stack traces.
Developers can use the CloudWatch Logs console or the AWS CLI to search, filter, and analyze these logs. This is crucial for debugging and troubleshooting.
- Custom Metrics and Logging: Developers can also add custom metrics and log statements to their Lambda functions using the AWS SDKs or standard logging libraries. This allows for more granular monitoring of specific application logic and behavior. For example, a developer could track the number of successful database queries or the time taken to process a specific task.
- Monitoring Tools: Beyond CloudWatch, several third-party monitoring tools integrate with Lambda, offering advanced features such as distributed tracing, application performance monitoring (APM), and anomaly detection. These tools can provide deeper insights into application performance and help identify potential bottlenecks or issues.
Monitoring and Logging Containerized Applications on Fargate
Monitoring and logging containerized applications on Fargate leverage a combination of AWS services, including CloudWatch, CloudWatch Container Insights, and container-specific logging drivers. The process is designed to provide comprehensive visibility into container performance, resource utilization, and application behavior.
- CloudWatch Container Insights: CloudWatch Container Insights is a dedicated service for monitoring containerized applications. It automatically collects metrics from container instances, tasks, and pods, providing a pre-built dashboard with key performance indicators (KPIs). This dashboard includes metrics such as:
- CPU utilization.
- Memory utilization.
- Network I/O.
- Disk I/O.
Container Insights also provides detailed performance information for individual containers and tasks, allowing for granular analysis of resource consumption.
- Log Collection: Fargate supports various logging drivers that send container logs to CloudWatch Logs. The default driver is the `awslogs` driver, which automatically forwards logs from the container’s standard output and standard error streams to CloudWatch Logs. Other logging drivers, such as `fluentd` and `syslog`, can be configured to send logs to other destinations or perform more advanced log processing.
- Log Analysis: Logs sent to CloudWatch Logs can be analyzed using CloudWatch Logs Insights, a query language that allows for searching, filtering, and aggregating log data. This is essential for troubleshooting application issues, identifying performance bottlenecks, and detecting security threats. For instance, a developer could use Logs Insights to identify the frequency of specific error messages or to track the performance of API calls.
- Custom Metrics: Developers can emit custom metrics from their containerized applications using the CloudWatch SDK or the CloudWatch agent. This enables the tracking of application-specific metrics, such as the number of requests processed or the latency of specific operations. These custom metrics can then be used to create custom dashboards and set alarms.
- Third-Party Integrations: Similar to Lambda, Fargate integrates with various third-party monitoring and logging tools. These tools can provide advanced features such as distributed tracing, APM, and anomaly detection, further enhancing the observability of containerized applications.
Comparing the Monitoring and Logging Capabilities of Lambda and Fargate
The following table provides a comparison of the monitoring and logging capabilities of Lambda and Fargate.
| Feature | Lambda | Fargate | Notes |
|---|---|---|---|
| Metrics Collection | Automatic collection of key metrics (invocations, errors, duration, etc.) via CloudWatch. | CloudWatch Container Insights provides automatic metrics for CPU, memory, network, and disk utilization at the container, task, and pod levels. | Lambda provides a more focused set of metrics, while Fargate offers broader resource-level metrics. |
| Log Aggregation | Automatic logging to CloudWatch Logs. Detailed logs include execution start/end times, function input/output, and log statements. | Support for various logging drivers (e.g., `awslogs`) sending logs to CloudWatch Logs. Container logs are captured from standard output/error streams. | Both platforms provide automatic log aggregation to CloudWatch Logs. Fargate offers more flexibility with logging drivers. |
| Custom Metrics | Support for custom metrics via AWS SDKs or standard logging libraries. | Support for custom metrics via CloudWatch SDK or CloudWatch agent. | Both platforms allow developers to define and track custom application-specific metrics. |
| Monitoring Tools Integration | Integration with third-party monitoring tools (APM, distributed tracing). | Integration with third-party monitoring tools (APM, distributed tracing). | Both platforms support integration with a wide range of monitoring tools for advanced features. |
Closure
In conclusion, both AWS Lambda and Fargate offer compelling serverless solutions, each suited for different application scenarios. Lambda excels in event-driven, stateless workloads requiring rapid scaling and cost-effectiveness. Fargate provides a container-native approach, simplifying the deployment and management of containerized applications while abstracting away infrastructure concerns. The optimal choice hinges on a thorough evaluation of workload characteristics, operational requirements, and cost considerations.
By carefully weighing these factors, developers can leverage the power of serverless computing to build scalable, resilient, and cost-efficient applications.
Frequently Asked Questions
What are the primary cost drivers for Lambda and Fargate?
Lambda costs are primarily driven by the number of requests, the duration of execution, and the amount of memory allocated. Fargate costs are primarily determined by the vCPU and memory resources requested for the container tasks, and the duration the tasks are running.
Which service offers more control over the underlying infrastructure?
Fargate offers less control over the underlying infrastructure compared to traditional container deployments, but provides more control than Lambda. Lambda abstracts away almost all infrastructure management.
Can Lambda and Fargate be used together?
Yes, Lambda and Fargate can be integrated. For example, a Lambda function can trigger a Fargate task, or Fargate can be used to host a service that is invoked by a Lambda function.
What are the typical latency characteristics of Lambda and Fargate?
Lambda generally exhibits lower cold start latency compared to Fargate, making it well-suited for use cases where rapid response times are critical. Fargate’s latency can vary depending on container image size and startup complexity.