Google Cloud Functions, a serverless execution environment, empowers developers to deploy and manage code without the complexities of server infrastructure. This paradigm shift allows for event-driven applications, where functions respond to triggers like HTTP requests, data uploads, or messages in a queue. By abstracting away the underlying infrastructure, Cloud Functions facilitate rapid development cycles, efficient resource utilization, and automatic scaling based on demand.
This guide will delve into the practical aspects of utilizing Cloud Functions, offering a structured approach to understanding its capabilities and implementing effective solutions.
We will explore the fundamental concepts of Cloud Functions, including its trigger mechanisms (HTTP, Cloud Storage, Pub/Sub), setup procedures, and deployment strategies. The subsequent sections will detail the process of creating, deploying, and managing functions in various languages (Node.js, Python, Go), while also covering essential aspects like dependency management, monitoring, security, and advanced use cases. Furthermore, this guide will offer insights into integrating Cloud Functions with other Google Cloud services, providing a holistic view of its potential in building scalable and resilient applications.
Introduction to Google Cloud Functions
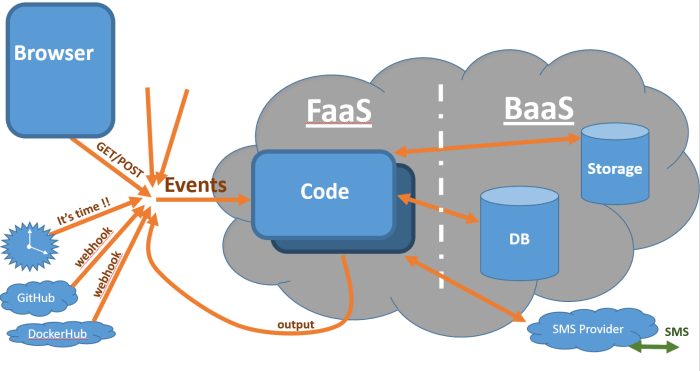
Google Cloud Functions provides a serverless execution environment for building and connecting cloud services. It allows developers to write and deploy code without managing servers or infrastructure, focusing solely on the code itself. This “Functions-as-a-Service” (FaaS) model automatically scales the infrastructure, handles operational tasks, and integrates with other Google Cloud services, promoting efficient resource utilization and accelerated development cycles.Cloud Functions excels at event-driven applications, allowing developers to respond to triggers from various sources, simplifying the creation of scalable and responsive systems.
It supports multiple programming languages, including Node.js, Python, Go, Java, .NET, and Ruby, providing flexibility for developers to use their preferred tools and frameworks. This approach reduces operational overhead, allowing developers to concentrate on business logic and deliver features faster.
Supported Trigger Types
Cloud Functions are designed to be triggered by various events, enabling a wide range of use cases. Understanding the supported trigger types is crucial for designing and implementing event-driven architectures.The primary trigger types include:
- HTTP Triggers: Allow functions to be invoked via HTTP requests. These functions are accessed through a unique URL, enabling direct integration with web applications, APIs, and other services. HTTP triggers are ideal for building REST APIs, webhooks, and handling user interactions.
- Cloud Storage Triggers: Respond to events within Google Cloud Storage, such as object creation, deletion, or metadata updates. This enables automated processing of files uploaded to Cloud Storage, including image resizing, video transcoding, and data analysis. For example, when a new image is uploaded to a Cloud Storage bucket, a Cloud Function can automatically resize the image and store it in a different bucket.
- Cloud Pub/Sub Triggers: Trigger functions based on messages published to Google Cloud Pub/Sub topics. This enables asynchronous communication and event-driven architectures. Cloud Pub/Sub triggers are suitable for building event-driven pipelines, processing streams of data, and decoupling services. For instance, a function can process real-time data streams from IoT devices.
- Cloud Firestore Triggers: Respond to changes in Cloud Firestore, including document creation, updates, and deletions. This allows for real-time data processing and synchronization between applications. Cloud Firestore triggers are useful for building real-time applications, synchronizing data across devices, and implementing data validation rules.
- Firebase Realtime Database Triggers: Similar to Cloud Firestore triggers, but for Firebase Realtime Database. Functions can be triggered by database events, enabling real-time data processing and application logic. This is used to update data in response to database changes.
- Cloud Scheduler Triggers: Enable functions to be executed on a scheduled basis. This allows for automating tasks such as data backups, report generation, and periodic maintenance. Cloud Scheduler is used to automate periodic tasks like sending emails or updating database records.
- Cloud Eventarc Triggers: Enable functions to react to events from various Google Cloud services, including Cloud Build, Cloud Audit Logs, and custom events. This allows for building sophisticated event-driven systems that react to a wide range of events within the Google Cloud ecosystem. For example, when a new build is triggered in Cloud Build, a Cloud Function can be invoked to send a notification.
Use Cases for Google Cloud Functions
Google Cloud Functions are well-suited for a variety of use cases, enabling developers to build scalable, cost-effective, and event-driven applications. The following are some prominent examples.
- Webhooks and API Backends: Cloud Functions can be used to build simple API endpoints and handle webhooks. They provide a lightweight and scalable solution for handling incoming HTTP requests. For example, a function can be used to receive data from a third-party service and process it.
- Data Processing and Transformation: Cloud Functions can be triggered by events such as file uploads to Cloud Storage or messages published to Cloud Pub/Sub, enabling data processing and transformation tasks. This includes tasks such as image resizing, video transcoding, and data cleaning. For example, a function can be triggered when a new CSV file is uploaded to Cloud Storage, parsing the data and storing it in a BigQuery table.
- Real-time Data Processing: Cloud Functions can be used to process real-time data streams from various sources, such as IoT devices or social media feeds. They can be triggered by events such as messages published to Cloud Pub/Sub or changes in Cloud Firestore, enabling real-time analytics and insights. For instance, a function can be used to analyze real-time data from IoT sensors and trigger alerts based on specific conditions.
- Backend for Mobile and Web Applications: Cloud Functions can serve as the backend for mobile and web applications, providing a scalable and cost-effective solution for handling application logic and data processing. They can be used to implement features such as user authentication, data storage, and push notifications. For example, a function can be used to handle user authentication and store user data in a database.
- Automated Tasks and Scheduled Jobs: Cloud Functions can be scheduled to run periodically using Cloud Scheduler, automating tasks such as data backups, report generation, and periodic maintenance. This enables developers to automate repetitive tasks and ensure that their applications are running smoothly. For instance, a function can be scheduled to generate daily reports and send them via email.
- Integration with Third-Party Services: Cloud Functions can be used to integrate with third-party services, such as payment gateways, social media platforms, and CRM systems. They can be triggered by events from these services or used to trigger actions in these services. For example, a function can be used to process payments using a payment gateway.
Setting Up Your Google Cloud Environment
Setting up your Google Cloud environment is a critical first step in deploying and managing Cloud Functions. This involves establishing a project, enabling the necessary APIs, and configuring the tools required to interact with the Google Cloud platform. Properly configuring your environment ensures secure and efficient function deployment and operation.
Creating a Google Cloud Project and Enabling the Cloud Functions API
The creation of a Google Cloud project serves as the organizational unit for all your Google Cloud resources, including Cloud Functions. Enabling the Cloud Functions API makes the service available for your project.To create a Google Cloud project:
- Navigate to the Google Cloud Console ([https://console.cloud.google.com/](https://console.cloud.google.com/)).
- If you don’t have a project, you will be prompted to create one. Click on the project dropdown in the top navigation bar, and then click “New Project”.
- Provide a project name and select an organization and billing account. The project name should be descriptive and unique within your organization.
- Click “Create”. The project creation process may take a few moments.
After creating the project, enable the Cloud Functions API:
- From the Google Cloud Console, ensure you have selected the newly created project.
- Search for “Cloud Functions” in the search bar at the top of the console.
- Click on “Cloud Functions” from the search results. If the API is not enabled, you will be prompted to enable it.
- Click “Enable” to activate the Cloud Functions API for your project.
This process registers your project with the Cloud Functions service, allowing you to deploy and manage functions. The API enables the underlying infrastructure for function execution, scaling, and monitoring. Failure to enable the API will prevent any function deployment.
Setting Up Authentication and Authorization for Cloud Functions
Authentication and authorization are essential for securing Cloud Functions and controlling access to their resources. Authentication verifies the identity of users or services, while authorization determines what actions they are permitted to perform.Authentication and authorization are typically managed using Google Cloud’s Identity and Access Management (IAM) system.
- Authentication: Cloud Functions can be authenticated using service accounts, which are special Google accounts that belong to your application rather than an individual user. When a function is deployed, a default service account is typically assigned, or you can specify a custom service account. This service account is used by the function to interact with other Google Cloud services. The default service account is named `
[email protected]`. You can view your project number in the Cloud Console project settings. - Authorization: Authorization is managed through IAM roles. IAM roles define a set of permissions that grant access to specific Google Cloud resources. For Cloud Functions, you can assign roles to the service account associated with the function. Common roles include:
- `roles/cloudfunctions.developer`: Allows the service account to deploy and manage Cloud Functions.
- `roles/storage.objectViewer`: Allows the function to read objects from Cloud Storage.
- `roles/pubsub.publisher`: Allows the function to publish messages to Pub/Sub.
These roles are granted at the project level, or on specific resources (e.g., a specific Cloud Storage bucket).
- Configuring IAM Roles: To assign an IAM role to a service account:
- Navigate to the IAM & Admin section in the Google Cloud Console.
- Select “IAM”.
- Locate the service account you want to modify.
- Click the “Edit” icon (pencil) for that service account.
- Click “Add Another Role”.
- Select the desired role from the dropdown menu.
- Click “Save”.
Properly configured authentication and authorization prevent unauthorized access and ensure that your Cloud Functions operate securely.
Installing and Configuring the Google Cloud SDK (gcloud CLI)
The Google Cloud SDK provides the command-line interface (gcloud CLI) and other tools for interacting with Google Cloud services, including Cloud Functions. The gcloud CLI is essential for deploying, managing, and monitoring your functions.
Installing and configuring the Google Cloud SDK:
- Download the SDK: Visit the Google Cloud SDK download page ([https://cloud.google.com/sdk/docs/install](https://cloud.google.com/sdk/docs/install)) and download the appropriate installer for your operating system (Windows, macOS, or Linux).
- Installation: Follow the instructions provided by the installer. This typically involves running the installer and accepting the terms and conditions. On Linux, you may need to add the `gcloud` command to your system’s PATH.
- Initialization: After installation, initialize the gcloud CLI by running the following command in your terminal:
gcloud initThis command will guide you through authenticating with your Google account and selecting the Google Cloud project you want to work with.
- Authentication: The `gcloud init` command will open a web browser where you will be prompted to sign in with your Google account. This allows the gcloud CLI to authenticate with Google Cloud on your behalf.
- Project Selection: After successful authentication, you will be prompted to select a Google Cloud project. Choose the project you created earlier.
- Configuration Verification: Verify your gcloud CLI configuration by running the following command:
gcloud config listThis command displays your current configuration, including the active project, account, and region settings. Ensure that the project displayed is the correct one.
- Optional Component Installation: The Google Cloud SDK includes various components, such as the Cloud Functions CLI, which is often installed by default. You can install additional components if needed using the following command:
gcloud components installFor example, to install the Cloud Functions CLI, although it is usually installed by default, you might run `gcloud components install cloud-functions`.
The gcloud CLI provides a powerful and flexible way to manage your Cloud Functions, making it an indispensable tool for developers. The configuration process ensures the CLI is correctly authenticated and connected to your Google Cloud project. Failure to correctly initialize the gcloud CLI will prevent the deployment and management of your functions.
Writing Your First Cloud Function
Creating a functional “Hello, World!” application serves as the foundational step in understanding and utilizing Google Cloud Functions. This initial implementation allows for the verification of the environment setup and the basic deployment process. Subsequent modifications and extensions can then build upon this fundamental understanding.
Design and Implementation of a “Hello, World!” Cloud Function
The “Hello, World!” function serves as a benchmark for cloud function execution. This function receives a request, processes it, and returns a pre-defined response. The choice of programming language influences the syntax and structure, but the core principles remain consistent.
Here’s how the function is designed and implemented:
* Node.js Example:
The Node.js implementation leverages the `http` module for handling HTTP requests.
“`javascript
/
– Responds to any HTTP request.
–
– @param !express:Request req HTTP request context.
– @param !express:Response res HTTP response context.
-/
exports.helloWorld = (req, res) =>
let message = req.query.message || req.body.message || ‘Hello, World!’;
res.status(200).send(message);
;
“`
This code defines a function named `helloWorld` that is exported. It accepts `req` (request) and `res` (response) objects as arguments. The function retrieves a message from the query parameters or the request body. If no message is provided, it defaults to “Hello, World!”. Finally, it sends the message in the response with a 200 status code.
* Python Example:
The Python implementation uses the `functions_framework` library to handle HTTP requests.
“`python
from flask import escape
from functions_framework import http
@http
def hello_world(request):
“””HTTP Cloud Function.
Args:
request (flask.Request): The request object.
Returns:
The response text, or any set of values that can be turned into a
Response object using `flask.make_response`.
“””
request_json = request.get_json(silent=True)
request_args = request.args
if request_json and ‘message’ in request_json:
message = request_json[‘message’]
elif request_args and ‘message’ in request_args:
message = request_args[‘message’]
else:
message = ‘Hello, World!’
return f’escape(message)’
“`
This code imports the `escape` function and the `http` decorator from the `functions_framework` library. The `@http` decorator registers the `hello_world` function to handle HTTP requests. The function retrieves a message from the request’s JSON body or query parameters, defaulting to “Hello, World!”. It then escapes the message using `escape` and returns it.
* Go Example:
The Go implementation uses the `net/http` package to handle HTTP requests.
“`go
package hello
import (
“fmt”
“net/http”
)
// HelloHTTP is an HTTP Cloud Function.
func HelloHTTP(w http.ResponseWriter, r
-http.Request)
fmt.Fprint(w, “Hello, World!”)
“`
This code defines a function named `HelloHTTP` that is exported. It takes `http.ResponseWriter` and `http.Request` as arguments. The function uses `fmt.Fprint` to write “Hello, World!” to the response writer.
Deployment of the Function using the `gcloud` CLI
The Google Cloud SDK’s `gcloud` command-line interface (CLI) provides a means to deploy the function to Google Cloud Functions. This process involves specifying the function’s source code, runtime environment, and other relevant configurations.
The deployment process involves these steps:
1. Initialization and Authentication: Ensure the Google Cloud SDK is installed and authenticated using `gcloud auth login` and `gcloud config set project [PROJECT_ID]`, replacing `[PROJECT_ID]` with the project ID.
2. Navigate to the Function’s Directory: Change the directory to where the function’s source code is located.
3.
Deploy the Function: Use the `gcloud functions deploy` command, specifying the function’s name, the runtime, the entry point (the function to be executed), and any other necessary configurations.
– Node.js Example Deployment:
“`bash
gcloud functions deploy helloWorld –runtime nodejs18 –trigger-http –entry-point helloWorld
“`
This command deploys the `helloWorld` function using the Node.js 18 runtime. The `–trigger-http` flag indicates that the function will be triggered by HTTP requests. The `–entry-point helloWorld` flag specifies that the `helloWorld` function is the entry point.
– Python Example Deployment:
“`bash
gcloud functions deploy hello_world –runtime python311 –trigger-http –entry-point hello_world
“`
This command deploys the `hello_world` function using the Python 3.11 runtime. The `–trigger-http` flag indicates that the function will be triggered by HTTP requests. The `–entry-point hello_world` flag specifies that the `hello_world` function is the entry point. The runtime version can be adjusted based on the project’s specific requirements.
– Go Example Deployment:
“`bash
gcloud functions deploy HelloHTTP –runtime go120 –trigger-http –entry-point HelloHTTP
“`
This command deploys the `HelloHTTP` function using the Go 1.20 runtime. The `–trigger-http` flag indicates that the function will be triggered by HTTP requests. The `–entry-point HelloHTTP` flag specifies that the `HelloHTTP` function is the entry point.
4. Verify Deployment: After successful deployment, the `gcloud` CLI will provide the URL for the deployed function. Test the function by accessing this URL in a web browser or using a tool like `curl`.
Function Structure: Handler Function and Dependencies
Cloud Functions are structured around a handler function, which serves as the entry point for execution. This function receives input, processes it, and produces output. The structure also includes dependencies that the function relies on.
The function’s structure encompasses these elements:
* Handler Function: This is the core function that executes when the function is triggered. It takes input parameters (e.g., an HTTP request object) and returns a response. The specific signature and parameters depend on the runtime and the trigger type.
– Dependencies: These are libraries or modules that the function requires to execute its logic.
These dependencies are specified in a configuration file (e.g., `package.json` for Node.js, `requirements.txt` for Python, or `go.mod` for Go). When deploying the function, the Google Cloud Functions platform installs these dependencies in the execution environment.
– Node.js Dependencies:
The `package.json` file specifies the project dependencies.
“`json
“name”: “hello-world”,
“version”: “1.0.0”,
“description”: “A simple Hello World function”,
“main”: “index.js”,
“dependencies”:
“express”: “^4.18.2”
,
“devDependencies”:
“mocha”: “^10.2.0”
,
“engines”:
“node”: “18”
“`
The example shows the `express` dependency, a web application framework. The `engines` field specifies the Node.js runtime version.
– Python Dependencies:
The `requirements.txt` file lists the Python dependencies.
“`text
Flask==2.3.3
functions-framework==3.2.0
“`
This example shows `Flask` and `functions-framework` as dependencies.
– Go Dependencies:
Go manages dependencies using modules. The `go.mod` file lists the project dependencies.
“`go
module example.com/hello
go 1.20
require (
google.golang.org/api v0.149.0
)
“`
The example indicates the `google.golang.org/api` package as a dependency.
These dependencies are crucial for the function’s functionality and must be correctly specified and managed for the function to operate as intended.
Triggering Cloud Functions

Cloud Functions can be triggered by various events, enabling serverless execution in response to changes in data, events from other services, or direct user requests. This section focuses on triggering Cloud Functions via HTTP requests, a fundamental mechanism for building web APIs and integrating with external systems. This approach allows developers to create functions that respond to webhooks, build simple web applications, or expose functionality through a RESTful interface.
Creating a Cloud Function Triggered by an HTTP Request
To create an HTTP-triggered Cloud Function, specific configurations and code are required. This process involves deploying a function that is accessible via a unique URL, responding to HTTP requests with defined methods (GET, POST, etc.), and handling request parameters and responses.
The following steps Artikel the process:
- Function Definition: The function must be defined to accept an HTTP request. This is typically achieved through a function signature that includes parameters representing the request object and, optionally, a response object. The request object contains information about the incoming HTTP request, such as headers, parameters, and the request body.
- Trigger Configuration: During deployment, the function must be configured to use an HTTP trigger. This is typically specified through the Cloud Functions deployment command or through the Cloud Console interface. The trigger configuration instructs Google Cloud to create an HTTP endpoint for the function.
- Code Implementation: Inside the function, the code processes the incoming HTTP request and generates an HTTP response. This involves parsing request parameters, performing computations, interacting with other services, and constructing the response body and headers.
- Deployment and URL Retrieval: After the code is written and the trigger is configured, the function is deployed to Google Cloud. Upon successful deployment, Google Cloud provides a unique URL for the function. This URL serves as the endpoint for HTTP requests.
Testing the HTTP Function
After deploying an HTTP-triggered Cloud Function, it’s crucial to verify its functionality through testing. This process confirms that the function correctly handles HTTP requests and generates the expected responses. Testing can be performed using various tools, including command-line utilities like `curl` and web browsers.
Here are the steps involved in testing an HTTP function:
- Retrieving the Function URL: After deployment, the Cloud Console provides the function’s URL. This URL is the endpoint to which HTTP requests are sent.
- Using `curl`: `curl` is a command-line tool for transferring data with URLs. It can be used to send various HTTP requests (GET, POST, PUT, DELETE) to the function’s URL. For example, to send a GET request, the command would be:
curl [FUNCTION_URL] - Using a Web Browser: A web browser can be used to send GET requests to the function’s URL. Simply typing the URL into the browser’s address bar and pressing Enter will send a GET request.
- Inspecting the Response: The response from the function should be examined to verify its correctness. This includes checking the response body, HTTP status code, and any headers. For example, a successful GET request might return a 200 OK status code and a JSON payload in the response body.
- Testing Different Request Types: The function should be tested with different HTTP methods (GET, POST, etc.) and with various request parameters and payloads to ensure it handles all cases correctly.
Handling HTTP Request Parameters and Responses
HTTP-triggered Cloud Functions need to effectively handle request parameters and generate appropriate responses. This involves extracting information from the incoming request and constructing the outgoing response, including the response body, HTTP status code, and headers.
The following aspects are crucial:
- Request Parameters: HTTP requests can include parameters in various forms:
- Query Parameters: These are included in the URL after a question mark (?). For example,
https://example.com/function?param1=value1¶m2=value2. - Path Parameters: These are embedded in the URL path itself. For example,
https://example.com/function/value1/value2. The function needs to parse the URL to extract the values. - Request Body: For POST, PUT, and PATCH requests, the request body typically contains data in formats like JSON or XML. The function must parse the body to extract the data.
The function’s code needs to access and process these parameters accordingly.
- Query Parameters: These are included in the URL after a question mark (?). For example,
- Response Body: The response body contains the data that the function returns to the client. This can be plain text, HTML, JSON, or any other format. The function must construct the response body based on the request and any processing performed.
- HTTP Status Codes: The HTTP status code indicates the outcome of the request. Common status codes include:
- 200 OK: Successful request.
- 201 Created: Resource successfully created.
- 400 Bad Request: The request was malformed.
- 401 Unauthorized: Authentication is required.
- 403 Forbidden: The server understood the request, but refuses to authorize it.
- 404 Not Found: The requested resource was not found.
- 500 Internal Server Error: An unexpected error occurred on the server.
The function must set the appropriate status code to reflect the outcome.
- Response Headers: Response headers provide additional information about the response, such as the content type (e.g.,
Content-Type: application/json) and caching directives. The function can set headers to control how the response is handled by the client. - Example (Python):
from flask import Flask, request, jsonify app = Flask(__name__) @app.route('/', methods=['GET', 'POST']) def hello_world(): if request.method == 'GET': name = request.args.get('name', 'World') return jsonify('message': f'Hello, name!'), 200 elif request.method == 'POST': data = request.get_json() name = data.get('name', 'World') return jsonify('message': f'Hello, POST name!'), 200 else: return jsonify('error': 'Method Not Allowed'), 405This example demonstrates how to handle GET and POST requests, extract parameters, and return JSON responses with different status codes. The code uses the Flask framework to simplify HTTP request handling. The function checks the HTTP method and processes request parameters differently. It uses the
request.args.get()method to get the ‘name’ query parameter from a GET request and therequest.get_json()method to parse the JSON body of a POST request.
Triggering Cloud Functions
Cloud Functions can be triggered by various events, allowing for automated responses to actions within your Google Cloud environment. One of the most common and useful triggers is based on changes within Google Cloud Storage. This functionality enables real-time processing of data uploaded to storage buckets, making it a powerful tool for tasks like image manipulation, data transformation, and more.
Cloud Storage Trigger Setup
Setting up a Cloud Function to be triggered by Cloud Storage events involves configuring the function to listen for specific events within a designated bucket. This typically involves selecting the event type (e.g., `google.storage.object.finalize` for new object creation, `google.storage.object.delete` for object deletion) and specifying the Cloud Storage bucket to monitor.
- Event Types: Cloud Storage triggers support different event types, allowing for fine-grained control over when a function is executed. The most common events include:
- `google.storage.object.finalize`: This event is triggered when a new object is created or an existing object is overwritten in the specified bucket. It’s useful for processing uploaded files immediately.
- `google.storage.object.delete`: This event is triggered when an object is deleted from the bucket. It’s suitable for cleanup tasks or removing associated data.
- `google.storage.object.archive`: This event is triggered when a live object is archived, typically transitioning to a cheaper storage class.
- `google.storage.object.metadataUpdate`: This event is triggered when the metadata of an object is updated.
- Bucket Configuration: When creating the Cloud Function, you’ll specify the Cloud Storage bucket to monitor. The function will then automatically subscribe to events within that bucket.
- IAM Permissions: The Cloud Function’s service account requires specific IAM (Identity and Access Management) permissions to access Cloud Storage resources. These permissions typically include `storage.objects.get` and `storage.objects.list` to read object data and `storage.objects.update` to modify objects, if the function needs to perform those actions.
Accessing Cloud Storage Object Data
Within the Cloud Function, you can access information about the Cloud Storage object that triggered the function. This data is passed to the function as an event payload, providing details such as the object’s name, bucket, size, content type, and other metadata. This information allows the function to process the object appropriately.
- Event Payload Structure: The event payload is a JSON object that contains details about the event. The specific structure depends on the event type. For `google.storage.object.finalize`, the payload typically includes:
- `bucket`: The name of the Cloud Storage bucket.
- `name`: The name of the object.
- `contentType`: The content type of the object (e.g., `image/jpeg`, `application/pdf`).
- `size`: The size of the object in bytes.
- `metadata`: A map of key-value pairs representing the object’s metadata.
- Object Retrieval: Using the bucket and object name from the event payload, the Cloud Function can retrieve the object’s content from Cloud Storage. This can be done using the Cloud Storage client libraries available for various programming languages (e.g., Python, Node.js, Go).
- Data Processing: Once the object’s content is retrieved, the Cloud Function can process it based on the application’s requirements. This could involve image resizing, text extraction, data transformation, or any other operation.
Image Processing Example: Resizing
A common use case for Cloud Storage triggers is image processing. This example demonstrates how to create a Cloud Function that resizes images uploaded to a Cloud Storage bucket.
- Function Logic: The Cloud Function would perform the following steps:
- Receive the `google.storage.object.finalize` event.
- Extract the bucket name, object name, and content type from the event payload.
- Check if the content type is an image (e.g., `image/jpeg`, `image/png`).
- Retrieve the image data from Cloud Storage.
- Resize the image using an image processing library (e.g., `Pillow` in Python).
- Upload the resized image back to Cloud Storage, potentially to a different bucket or with a modified name.
- Code Snippet (Python with Pillow):
from google.cloud import storage from PIL import Image import io def resize_image(event, context): """Resizes an image uploaded to Cloud Storage.""" bucket_name = event['bucket'] object_name = event['name'] content_type = event['contentType'] if not content_type.startswith('image/'): print(f'Skipping non-image object: object_name') return try: # Download the image from Cloud Storage client = storage.Client() bucket = client.get_bucket(bucket_name) blob = bucket.get_blob(object_name) image_data = blob.download_as_bytes() # Open the image using Pillow image = Image.open(io.BytesIO(image_data)) # Resize the image width, height = image.size new_width = 800 new_height = int(height- (new_width / width)) resized_image = image.resize((new_width, new_height)) # Upload the resized image to Cloud Storage output_bucket_name = bucket_name # Or a different bucket output_object_name = f'resized_object_name' output_blob = bucket.blob(output_object_name) output_io = io.BytesIO() resized_image.save(output_io, format=image.format) output_blob.upload_from_string(output_io.getvalue(), content_type=content_type) print(f'Resized image saved to: gs://output_bucket_name/output_object_name') except Exception as e: print(f'Error processing image: e') Triggering Cloud Functions
Cloud Functions offer diverse triggering mechanisms, allowing them to respond to various events within the Google Cloud ecosystem. Among these, Cloud Pub/Sub triggers provide a robust and scalable way to react to asynchronous message streams. This approach is particularly useful for building event-driven architectures, where different components of a system can communicate and coordinate their actions through message passing.
Cloud Pub/Sub Triggers: Creation and Functionality
Cloud Pub/Sub triggers enable Cloud Functions to react to messages published to a specific Pub/Sub topic. This functionality is central to designing systems that are responsive to real-time data and events. The core process involves configuring the function to listen for messages on a designated topic. When a new message arrives, the Cloud Function is automatically invoked.
To create a Cloud Function triggered by Cloud Pub/Sub, several steps are involved:
- Function Deployment with Trigger Configuration: During deployment, the function must be configured with a Pub/Sub trigger. This specifies the Pub/Sub topic the function will subscribe to. This configuration is usually handled through the Google Cloud Console, the gcloud CLI, or Infrastructure as Code (IaC) tools like Terraform.
- Message Reception and Function Invocation: When a message is published to the configured Pub/Sub topic, Google Cloud Pub/Sub automatically detects this and invokes the corresponding Cloud Function. The function then receives the message as input.
- Message Processing within the Function: Inside the Cloud Function, the code processes the received message. This often involves parsing the message data, performing necessary operations (e.g., data transformation, database updates, external API calls), and optionally producing new messages to other Pub/Sub topics or triggering other functions.
The flexibility of Cloud Pub/Sub triggers makes them suitable for various use cases. For example, consider a system that processes user activity data. A Cloud Function, triggered by a Pub/Sub topic that receives user activity events, could be used to:
- Update a user profile in a database.
- Trigger a notification to the user.
- Analyze user behavior to identify trends.
Publishing Messages to Pub/Sub with gcloud CLI
The `gcloud` command-line interface (CLI) provides a straightforward method for publishing messages to Cloud Pub/Sub topics. This is useful for testing, debugging, and integrating with other services. The basic command structure is as follows:
gcloud pubsub topics publish TOPIC_NAME --message "MESSAGE_DATA"
Where:
TOPIC_NAMEis the name of the Pub/Sub topic.--messagespecifies the message data to be published. The message data must be a string.
For instance, to publish a JSON message to a topic named “my-topic”, you might use the following command:
gcloud pubsub topics publish my-topic --message '"event": "user_signup", "user_id": "12345"'
In this example, the command publishes a JSON string representing a “user_signup” event. The data is encoded in the JSON format, which is commonly used for structured data exchange in modern applications. The gcloud CLI automatically handles the necessary encoding and transmission of the message to the specified Pub/Sub topic. This approach allows developers to quickly test the behavior of Cloud Functions that are triggered by Pub/Sub messages, ensuring that they correctly handle the data being sent.
Parsing and Processing Pub/Sub Message Data
Within a Cloud Function triggered by Pub/Sub, the message data is accessible through the function’s input argument. The structure of this input depends on the programming language used. Generally, the input will contain the message payload and metadata, such as the message ID and publish time.
For instance, in Python, the input is typically a dictionary-like object. Accessing the message data involves parsing the message payload, which is often a string encoded in a specific format, such as JSON.
Here’s a simplified example of a Python Cloud Function that processes a JSON message:
“`python
import json
def process_pubsub_message(event, context):
“””
Cloud Function triggered by Pub/Sub.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
“””
try:
message = event[‘data’].decode(‘utf-8’)
data = json.loads(message)
print(f”Received message: data”)
# Perform actions based on the message data
if data.get(‘event’) == ‘user_signup’:
user_id = data.get(‘user_id’)
print(f”New user signup: user_id”)
# Add logic to update user profile or trigger another function
except Exception as e:
print(f”Error processing message: e”)
“`
In this example:
- The `event` argument contains the Pub/Sub message data.
- `event[‘data’]` holds the base64 encoded message payload, which is decoded to a string.
- `json.loads()` parses the JSON string into a Python dictionary.
- The code then accesses specific data elements (e.g., `data.get(‘event’)`, `data.get(‘user_id’)`) to process the message.
This function demonstrates a common pattern: decoding the base64-encoded payload, parsing the data based on its format (in this case, JSON), and then performing actions based on the data’s content. Error handling is crucial to prevent unexpected function failures. The `try…except` block catches potential exceptions during message processing, such as malformed JSON, ensuring that the function doesn’t crash and provides informative error messages.
This pattern is adaptable for various message formats, and it is scalable to handle high-volume message streams.
Managing Function Dependencies and Libraries
Effectively managing dependencies and libraries is crucial for creating robust and maintainable Google Cloud Functions. Properly handling these elements ensures code reusability, reduces development time, and minimizes the risk of runtime errors. This section will delve into the methodologies for dependency management and best practices for incorporating external libraries into your Cloud Function code, promoting efficient and scalable deployments.
Dependency Management with Package Managers
Dependency management relies on package managers that handle the inclusion of external libraries required by a Cloud Function. These tools automate the process of fetching, installing, and managing the versions of dependencies. Different package managers are used depending on the programming language selected for the Cloud Function.
- Node.js (npm): Node Package Manager (npm) is the default package manager for Node.js projects. It uses a `package.json` file to define project metadata, including dependencies. To install dependencies, navigate to the directory containing your `package.json` file and run the command `npm install`. This command downloads and installs all listed dependencies into a `node_modules` directory. Cloud Functions automatically recognize the `node_modules` directory and include its contents during deployment.
For example:
A `package.json` file might look like this:
"name": "my-cloud-function", "version": "1.0.0", "dependencies": "lodash": "^4.17.21"
Running `npm install` would download and install the `lodash` library, allowing it to be used within the Node.js Cloud Function.
- Python (pip): Python uses pip (Pip Installs Packages) as its package manager. The `requirements.txt` file specifies the dependencies required by the project. Dependencies are installed using the command `pip install -r requirements.txt`. When deploying a Python Cloud Function, the Cloud Functions build process automatically installs the packages listed in the `requirements.txt` file.
For example:
A `requirements.txt` file might look like this:
requests==2.28.1 google-cloud-storage==2.5.0
Running `pip install -r requirements.txt` would install the `requests` and `google-cloud-storage` libraries, making them available to the Python Cloud Function.
- Go (go modules): Go uses go modules for dependency management. The `go.mod` file defines the project’s modules and their dependencies. Dependencies are managed through commands like `go mod init` to initialize a new module, `go get` to add or update dependencies, and `go mod tidy` to remove unused dependencies. Cloud Functions for Go automatically uses the modules specified in the `go.mod` file during deployment.
For example:
A `go.mod` file might look like this:
module example.com/my-cloud-function go 1.19 require ( cloud.google.com/go/storage v1.30.1 )
The command `go mod tidy` ensures that all required modules are downloaded and available for the Go Cloud Function.
Best Practices for Including External Libraries
Adhering to best practices when incorporating external libraries enhances code quality, maintainability, and security. Careful consideration of these factors will contribute to more reliable and scalable Cloud Functions.
- Pinning Dependency Versions: Specifying exact versions of dependencies in your `package.json`, `requirements.txt`, or `go.mod` files is crucial. This prevents unexpected behavior caused by updates to external libraries that might introduce breaking changes. Use the version control mechanisms provided by the package manager (e.g., the caret `^` or tilde `~` in npm, or specific version numbers in pip) to control the range of acceptable versions.
For instance, using `requests==2.28.1` in `requirements.txt` guarantees that only version 2.28.1 of the `requests` library will be used, preventing compatibility issues that could arise from a later version.
- Regularly Updating Dependencies: While pinning versions is important for stability, it is equally important to periodically update dependencies to benefit from security patches, bug fixes, and performance improvements. Monitor your dependencies for updates and test your Cloud Functions thoroughly after upgrading. Tools like `npm outdated` (Node.js) or `pip list –outdated` (Python) can help identify outdated packages.
- Minimizing Dependencies: Avoid including unnecessary dependencies. Each dependency adds to the function’s size and can increase deployment time. Carefully evaluate the need for each library and choose lightweight alternatives whenever possible.
- Using a Virtual Environment (Python): When developing Python Cloud Functions, utilize virtual environments (e.g., using `venv` or `virtualenv`) to isolate your project’s dependencies. This prevents conflicts with system-level packages and ensures that only the required libraries are installed.
- Security Scanning: Regularly scan your dependencies for known vulnerabilities. Tools like `npm audit` (Node.js), `pip-audit` (Python), or dedicated vulnerability scanners can help identify and address security risks. This proactive approach ensures the security posture of your Cloud Functions.
Example: Using a Database Client Library
This example demonstrates how to integrate a database client library into a Cloud Function, focusing on the practical application of dependency management. The specific implementation will depend on the database system chosen (e.g., PostgreSQL, MySQL, MongoDB). The example uses Python with the `psycopg2` library for PostgreSQL.
- Project Setup: Create a new directory for your Cloud Function and initialize a Python project.
- Create a `requirements.txt` file:
Create a file named `requirements.txt` with the following content:
psycopg2-binary==2.9.6 google-cloud-secret-manager==2.19.1
- Write the Cloud Function code:
Create a file named `main.py` with the following content. This code connects to a PostgreSQL database using credentials stored in Google Cloud Secret Manager, executes a simple query, and returns the result.
import os import psycopg2 from google.cloud import secretmanager def get_secret(secret_id): client = secretmanager.SecretManagerServiceClient() name = f"projects/os.environ['GOOGLE_CLOUD_PROJECT']/secrets/secret_id/versions/latest" response = client.access_secret_version(name=name) return response.payload.data.decode("UTF-8") def postgres_query(request): try: # Retrieve database credentials from Secret Manager db_user = get_secret("db-user") db_password = get_secret("db-password") db_host = get_secret("db-host") db_name = get_secret("db-name") # Establish a connection to the PostgreSQL database conn = psycopg2.connect( host=db_host, database=db_name, user=db_user, password=db_password ) cur = conn.cursor() # Execute a sample query cur.execute("SELECT version();") version = cur.fetchone()[0] # Close the connection cur.close() conn.close() return f"PostgreSQL version: version" except Exception as e: return f"Error: str(e)" - Deploy the Cloud Function: Use the Google Cloud CLI to deploy the function. Make sure to configure environment variables for the database connection, and grant the Cloud Function the necessary permissions (e.g., Secret Manager access, Cloud SQL access).
gcloud functions deploy postgres-function \ --runtime python39 \ --trigger-http \ --region=us-central1 \ --env-vars-file=env.yaml \ --source=.
The `env.yaml` file should contain the environment variables used by the `main.py` file.
- Testing: After deployment, test the Cloud Function by sending an HTTP request to its URL. The response should indicate the PostgreSQL version.
This example illustrates how to integrate a database client, manage its dependencies, and incorporate best practices for secure and maintainable code.
Monitoring and Logging Cloud Functions
Effective monitoring and logging are crucial for maintaining the health, performance, and reliability of your Google Cloud Functions. These practices allow you to identify and address issues quickly, optimize function behavior, and ensure a positive user experience. This section will delve into the methods for viewing logs and metrics, implementing custom logging, and setting up alerts to proactively manage your Cloud Functions.
Viewing Function Logs and Metrics in the Google Cloud Console
The Google Cloud Console provides a comprehensive interface for monitoring the activity of your Cloud Functions. Understanding how to navigate and interpret the information presented is essential for effective function management.
To view logs:
- Navigate to the Cloud Functions section in the Google Cloud Console.
- Select the specific function you wish to monitor.
- Click on the “Logs” tab. This tab displays a chronological stream of logs generated by your function. Each log entry includes details such as the timestamp, the function’s execution ID, the log level (e.g., INFO, WARNING, ERROR), and the log message itself.
- You can filter and search the logs using various criteria, including log levels, specific text within the log messages, and the execution ID. This is useful for pinpointing specific issues or identifying patterns in your function’s behavior.
To view metrics:
- Stay within the Cloud Functions section and select the desired function.
- Click on the “Metrics” tab. This tab provides a graphical representation of key performance indicators (KPIs) for your function.
- Metrics include:
- Invocation Count: The total number of times the function has been executed. This metric helps you understand the function’s usage frequency.
- Execution Time: The average and percentile execution times of the function. This metric is critical for assessing performance and identifying potential bottlenecks.
- Errors: The number of errors encountered during function executions. Tracking errors is vital for identifying and resolving issues.
- Memory Used: The amount of memory used by the function during execution. Monitoring memory usage helps you optimize function configuration and prevent performance degradation.
- Network Egress: The amount of network data sent out by the function. Useful for identifying potential bandwidth issues.
- You can customize the time range displayed in the charts to analyze trends over different periods.
Implementing Custom Logging within Your Cloud Function Code
While Google Cloud Functions automatically log basic information, implementing custom logging allows for more detailed insights into your function’s operations. This involves strategically placing logging statements within your function code to capture relevant data and context.
To implement custom logging, you can use the standard logging libraries available in your function’s runtime environment. For example:
- Node.js: Use the `console.log()`, `console.info()`, `console.warn()`, and `console.error()` methods. Each method corresponds to a different log level.
- Python: Use the `logging` module. For example, `logging.info()`, `logging.warning()`, and `logging.error()`.
- Go: Use the `log` package, such as `log.Printf()` or `log.Println()`.
Example (Python):
“`python
import logging
def my_function(event, context):
logging.info(‘Function triggered’)
try:
# Your function logic here
result = some_operation()
logging.info(f’Operation successful: result’)
except Exception as e:
logging.error(f’An error occurred: str(e)’)
raise
“`
Example (Node.js):
“`javascript
exports.myFunction = (req, res) =>
console.log(‘Function triggered’);
try
// Your function logic here
const result = someOperation();
console.log(`Operation successful: $result`);
catch (error)
console.error(`An error occurred: $error`);
res.status(500).send(‘Internal Server Error’);
;
“`
The key is to strategically place these logging statements within your code to capture important events, variable values, and error conditions. This will allow you to diagnose issues more efficiently and track the performance of specific code sections. Use different log levels to categorize the severity of the information being logged.
Demonstrating How to Set Up Alerts for Function Errors or Performance Issues
Setting up alerts allows you to be proactively notified of critical events, such as function errors or performance degradation. Google Cloud Monitoring allows you to define alerting policies based on metrics collected from your Cloud Functions.
To set up alerts:
- Navigate to the “Monitoring” section in the Google Cloud Console.
- Select “Alerting” and then “Create Policy”.
- Define the condition for the alert.
- Choose the metric you want to monitor (e.g., “Errors,” “Execution Time”).
- Select the aggregation method (e.g., “Mean,” “Count”).
- Set the threshold and duration for the alert (e.g., “Errors greater than 0 for 5 minutes”).
- Configure the notification channels.
- Specify how you want to be notified (e.g., email, Slack, PagerDuty).
- Provide the necessary details for each notification channel.
- Review and save the alerting policy.
For example, to create an alert for function errors:
- In the “Create Policy” interface, select “Cloud Functions” as the resource type.
- Choose the “Errors” metric.
- Set the condition to “Errors > 0”.
- Configure a notification channel, such as email.
When an alert is triggered, you will receive a notification, allowing you to quickly investigate and resolve the issue. It is crucial to regularly review and adjust your alerting policies to ensure they are effective and relevant to your function’s behavior.
Configuring Function Settings
Configuring function settings is crucial for optimizing the performance, cost-effectiveness, and reliability of your Google Cloud Functions. Properly configured settings ensure that your functions have adequate resources to execute tasks efficiently, handle varying workloads, and maintain operational stability. Incorrect settings can lead to performance bottlenecks, increased costs, and function failures.
Memory Allocation
The memory allocated to a Cloud Function directly impacts its performance, particularly for computationally intensive tasks or those that process large datasets. Selecting the right memory allocation requires understanding the function’s resource requirements.
- Memory Limits: Cloud Functions offers a range of memory options, typically starting from a minimum value (e.g., 128MB) and increasing in increments. Choosing an appropriate memory allocation involves a trade-off between performance and cost.
- Impact on Performance: Functions with insufficient memory may experience longer execution times due to memory swapping or garbage collection overhead. This can lead to increased latency and potentially impact user experience.
- Determining Memory Needs: Analyze your function’s code to estimate its memory consumption. Tools like profiling and monitoring can help identify memory bottlenecks. Start with a baseline memory allocation and increase it incrementally while monitoring performance metrics.
- Example: Consider a function processing large images. If the image processing library requires significant memory for loading, processing, and outputting the result, allocating a higher memory setting will improve performance compared to a lower memory setting.
Timeout Configuration
The timeout setting defines the maximum execution time for a Cloud Function. This setting is critical for preventing functions from running indefinitely and consuming resources unnecessarily.
- Timeout Limits: Cloud Functions have a maximum timeout limit, which varies depending on the function’s environment. Setting a timeout that is too short can lead to premature function terminations, while a timeout that is too long can waste resources.
- Setting Appropriate Timeouts: Analyze the expected execution time of your function. Consider factors like network latency, data processing complexity, and external API response times. Set the timeout slightly higher than the expected execution time to accommodate potential delays.
- Handling Timeouts: Implement error handling to gracefully manage timeout scenarios. Log errors, retry operations (if appropriate), and provide informative feedback to users.
- Example: A function that calls an external API should have a timeout that accounts for potential network delays. If the API typically responds within 2 seconds, a timeout of 3-5 seconds would be appropriate to handle occasional delays.
CPU Allocation
The CPU allocation is directly proportional to the memory allocated. Cloud Functions automatically allocates CPU resources based on the selected memory. Higher memory allocations receive more CPU resources, which can improve the speed of compute-intensive operations.
- CPU and Memory Relationship: The amount of CPU allocated scales linearly with the memory. For instance, doubling the memory will approximately double the CPU available to the function.
- Impact on Performance: More CPU resources allow for faster execution of tasks, particularly those involving intensive computations or complex processing.
- Optimizing CPU Allocation: Monitor function performance and CPU utilization. If a function is CPU-bound (i.e., CPU utilization is consistently high), consider increasing the memory allocation to provide more CPU resources.
- Example: A function that performs video encoding will benefit significantly from increased CPU resources. By allocating more memory, the function will gain access to more CPU cores, accelerating the encoding process and reducing processing time.
Concurrency Settings
Concurrency settings determine the number of function instances that can run concurrently. This setting is critical for handling high traffic and ensuring scalability.
- Concurrency Limits: Cloud Functions allows you to configure the maximum number of concurrent function instances. This limit prevents a single function from monopolizing resources and ensures fair access for all requests.
- Scaling Based on Demand: The platform automatically scales the number of function instances based on incoming traffic. If the demand increases, the platform will launch more instances up to the configured concurrency limit.
- Managing Concurrency: Consider the function’s resource requirements and the expected traffic volume when setting the concurrency limit. A higher limit can handle more concurrent requests but also increases resource consumption.
- Example: If a function handles user authentication requests, and the application experiences a sudden surge in traffic, the concurrency setting will determine how many authentication requests can be processed simultaneously.
Environment Variables
Environment variables provide a mechanism to configure function behavior without modifying the code directly. This allows for flexibility and portability.
- Configuration Flexibility: Environment variables store configuration parameters, such as API keys, database connection strings, and feature flags.
- Security: Sensitive information, such as API keys, should be stored as environment variables to prevent them from being hardcoded in the function’s source code.
- Deployment Flexibility: Environment variables allow the same function code to be deployed in different environments (e.g., development, staging, production) with different configurations.
- Example: Instead of hardcoding a database connection string in your function, store it as an environment variable. This allows you to easily switch between different database instances without modifying the code.
Resource Limits Importance
Setting appropriate resource limits, including memory, timeout, and concurrency, is essential for several reasons:
- Cost Optimization: Properly configured resource limits prevent over-provisioning and ensure that you only pay for the resources your functions actually use.
- Performance Optimization: Setting adequate memory and CPU resources ensures that functions have sufficient resources to execute efficiently.
- Reliability and Stability: Timeout settings and concurrency limits prevent functions from running indefinitely or consuming excessive resources, which can lead to function failures or system instability.
- Security: Environment variables and other security measures are critical to protect sensitive data and prevent unauthorized access.
Scaling Cloud Functions
Cloud Functions automatically scales based on demand. The platform monitors incoming requests and automatically launches more function instances to handle the load.
- Automatic Scaling: Google Cloud Functions is designed to automatically scale based on the number of incoming requests. This means that the platform will dynamically provision more function instances to handle increased traffic.
- Concurrency Controls: The concurrency settings described above determine the maximum number of function instances that can run concurrently.
- Monitoring and Optimization: Regularly monitor function performance and resource utilization to identify potential bottlenecks and optimize function settings.
- Example: Consider a function that processes image uploads. When the application receives a large number of uploads, the platform will automatically launch more instances of the function to handle the increased workload.
Security Best Practices for Cloud Functions
Securing Google Cloud Functions is paramount to protecting sensitive data, maintaining application integrity, and ensuring the overall reliability of your serverless deployments. Implementing robust security measures mitigates risks associated with unauthorized access, data breaches, and malicious attacks. This section Artikels critical security considerations and best practices for safeguarding your Cloud Functions.
Service Account Usage for Secure Access
Cloud Functions leverage service accounts to authenticate and authorize access to other Google Cloud services. A service account acts as an identity for your function, allowing it to interact with resources like Cloud Storage, Cloud SQL, or other APIs. Employing service accounts correctly is fundamental to a secure architecture.
To securely utilize service accounts, follow these guidelines:
- Principle of Least Privilege: Grant service accounts only the necessary permissions required for their tasks. Avoid providing overly broad roles, such as `roles/owner`, which can expose your resources to unnecessary risks. Instead, assign specific roles that align with the function’s purpose, such as `roles/storage.objectViewer` for reading objects from Cloud Storage or `roles/cloudsql.client` for accessing Cloud SQL instances.
- Custom Roles: Consider creating custom roles with granular permissions if the predefined roles do not precisely meet your needs. This allows for precise control over access rights.
- Service Account Isolation: Assign a unique service account to each function or group of related functions to limit the blast radius of potential security breaches. If one function’s service account is compromised, the impact is contained.
- Service Account Configuration: Configure the service account associated with your function during deployment. This can be done using the `–service-account` flag in the `gcloud functions deploy` command or through the Google Cloud Console.
- Key Rotation: Regularly rotate the service account keys to minimize the impact of compromised credentials. While Google Cloud manages the service account keys, it is good practice to review and potentially regenerate the keys periodically.
For example, to deploy a Cloud Function that reads objects from a Cloud Storage bucket, you would use the following command, specifying the appropriate service account and granting the `roles/storage.objectViewer` role:
“`bash
gcloud functions deploy my-function –runtime python39 –trigger-http –service-account=my-function-service-account@my-project.iam.gserviceaccount.com –project=my-project
“`
In this scenario, the function only has permission to view objects within the specified Cloud Storage bucket, adhering to the principle of least privilege.
Restricting Access with Identity and Access Management (IAM)
IAM provides a powerful mechanism to control who (users, service accounts, or groups) has what access to your Cloud Functions. By leveraging IAM, you can implement fine-grained access control, ensuring that only authorized entities can invoke your functions.
To restrict access to your Cloud Functions, consider the following:
- Caller Identity: Determine the identity of the entity invoking the function. This can be a user account, a service account, or an external service.
- IAM Roles: Assign appropriate IAM roles to the caller. The `roles/cloudfunctions.invoker` role grants permission to invoke a Cloud Function. For HTTP-triggered functions, the `allUsers` and `allAuthenticatedUsers` predefined groups can be used to control public access. However, exercise caution when using these roles, as they grant broad access.
- Resource-Level Access Control: Apply IAM policies at the function level to restrict access to individual functions. You can use the Google Cloud Console, the `gcloud` command-line tool, or the IAM API to manage these policies.
- Context-Aware Access: Integrate Context-Aware Access to enforce access policies based on attributes like user identity, device posture, and location. This adds an extra layer of security.
- Network Policies: Implement network policies, such as VPC Service Controls, to limit the network access to your Cloud Functions. This helps prevent unauthorized access from outside your defined network perimeter.
For instance, to restrict access to a function to only members of a specific Google Group, you would add the following IAM binding:
“`bash
gcloud functions add-iam-policy-binding my-function –member=’group:[email protected]’ –role=’roles/cloudfunctions.invoker’ –project=my-project
“`
This command grants the `roles/cloudfunctions.invoker` role to the Google Group `[email protected]`, allowing only members of that group to invoke the function. Any other user or service account will be denied access.
By meticulously implementing these security practices, you significantly reduce the attack surface of your Cloud Functions, safeguarding your applications and data from potential threats.
Advanced Use Cases and Considerations
Google Cloud Functions, while a powerful tool for event-driven computing, offers a versatile platform that extends far beyond simple “hello world” examples. Its true potential unlocks when integrated with other Google Cloud services and utilized to address complex, real-world scenarios. This section delves into advanced use cases, explores interactions with other services like Cloud Run and Cloud SQL, and provides a comparative analysis with other serverless options, highlighting their strengths and weaknesses.
Cloud Functions Integration with Other Google Cloud Services
Cloud Functions thrives in a service-oriented architecture, seamlessly integrating with a wide array of Google Cloud services. This interoperability allows developers to build sophisticated applications by chaining functions together or triggering them based on events from other services.
- Cloud Run: Cloud Run provides a fully managed platform for running containerized applications. Cloud Functions can act as event triggers for Cloud Run services, allowing for more complex workflows. For example, a Cloud Function triggered by a file upload to Cloud Storage could invoke a Cloud Run service to process the image, perhaps resizing it or extracting metadata. This combination allows for the scalability of Cloud Run with the event-driven nature of Cloud Functions.
- Cloud Storage: Cloud Functions is frequently triggered by events in Cloud Storage, such as object creation, deletion, or modification. Use cases include image processing (resizing, watermarking), data validation, and data transformation.
- Cloud Pub/Sub: Cloud Pub/Sub is a messaging service that allows for asynchronous communication between applications. Cloud Functions can subscribe to Pub/Sub topics, enabling them to react to messages published by other services or applications. This is ideal for building decoupled systems, where components communicate through events rather than direct API calls.
- Cloud Firestore/Cloud Datastore: Functions can be triggered by changes in Cloud Firestore or Cloud Datastore databases. This is useful for real-time data processing, such as updating search indexes, triggering notifications, or performing data validation.
- Cloud SQL: Cloud Functions can interact with Cloud SQL databases using various database connectors (e.g., Cloud SQL Connector for PostgreSQL, MySQL, etc.). This allows functions to read from, write to, and modify data in relational databases.
- BigQuery: Functions can be used to load data into BigQuery, transform data before loading, or trigger BigQuery jobs. This is valuable for data warehousing and analytics.
- Cloud Translation/Cloud Natural Language/Cloud Vision: Functions can be used to interact with these services to process text, analyze images, or perform other AI/ML tasks. For example, a function could be triggered by a new blog post to translate it into multiple languages using Cloud Translation.
Scenario: Deploying a Function that Interacts with Cloud SQL
This scenario demonstrates how to deploy a Cloud Function that interacts with a Cloud SQL database. The function will be triggered by an HTTP request, and it will retrieve data from a PostgreSQL database.
- Prerequisites:
- A Google Cloud project.
- Cloud SQL for PostgreSQL instance.
- PostgreSQL client library (e.g., `pg`) installed in the function’s dependencies.
- Function Code (Node.js example):
const Client = require('pg'); / - Retrieves data from a PostgreSQL database. - - @param object req Cloud Function request context. - @param object res Cloud Function response context. -/ exports.getDataFromPostgres = async (req, res) => const client = new Client( user: 'your_db_user', host: 'your_db_host', // Cloud SQL instance IP address database: 'your_db_name', password: 'your_db_password', port: 5432, // Default PostgreSQL port ); try await client.connect(); const result = await client.query('SELECT- FROM your_table'); res.status(200).send(result.rows); catch (err) console.error('Error querying the database:', err); res.status(500).send('Error retrieving data from the database.'); finally await client.end(); ; - Deployment:
- Deploy the function using the Google Cloud Console or the `gcloud` command-line tool.
- Configure the function to use the Cloud SQL Connector for secure database access (recommended). This requires enabling the Cloud SQL Admin API and setting the appropriate permissions.
- Grant the Cloud Function service account the necessary permissions to access the Cloud SQL instance.
- Testing:
- Send an HTTP request to the function’s endpoint.
- Verify that the function retrieves data from the database and returns it in the response.
This example demonstrates a basic interaction. In a real-world scenario, the function could perform more complex operations, such as:
- Inserting new data into the database.
- Updating existing data.
- Performing data validation.
- Implementing business logic based on database data.
Comparing Cloud Functions with Other Serverless Options
Google Cloud offers several serverless computing options, each with its strengths and weaknesses. Understanding the differences between these options is crucial for choosing the right tool for the job. The table below compares Cloud Functions with Cloud Run and App Engine.
| Feature | Cloud Functions | Cloud Run | App Engine |
|---|---|---|---|
| Primary Use Case | Event-driven, short-lived tasks, integrations | Containerized applications, web applications, APIs | Web applications, backend services, scaling applications |
| Invocation | Event triggers (HTTP, Cloud Storage, Pub/Sub, etc.) | HTTP requests, gRPC, Pub/Sub | HTTP requests |
| Programming Languages | Node.js, Python, Go, Java, .NET, PHP, Ruby | Any language supported by Docker | Java, Python, Go, Node.js, PHP, Ruby, .NET |
| Containerization | No | Yes | Optional (Flexible Environment) |
| Maximum Execution Time | 9 minutes (HTTP triggers), 60 minutes (background triggers) | No limit (but recommended to design for statelessness and fast response times) | No limit |
| Scalability | Automatic | Automatic | Automatic |
| Pricing | Pay-per-use (based on execution time, memory, and invocations) | Pay-per-use (based on CPU, memory, and request count) | Pay-per-use (based on resource usage) |
| State Management | Stateless (designed for short-lived tasks) | Stateless (recommended) or stateful (using external services) | Stateful (can manage sessions and user data) |
| Ideal for |
|
|
|
This table provides a high-level overview. The optimal choice depends on the specific requirements of the application. Cloud Functions excels at event-driven processing and integration, while Cloud Run is a better choice for containerized applications and APIs. App Engine is well-suited for web applications with more complex state management requirements.
Closure
In conclusion, Google Cloud Functions presents a powerful and flexible platform for building serverless applications. This guide has provided a comprehensive overview of its core functionalities, from initial setup to advanced use cases. By understanding the different trigger types, managing dependencies, and adhering to security best practices, developers can leverage Cloud Functions to create scalable, cost-effective, and event-driven solutions. The future of cloud computing is undoubtedly serverless, and mastering Cloud Functions is a crucial step towards building modern, efficient, and resilient applications on the Google Cloud Platform.
FAQ
What programming languages are supported by Google Cloud Functions?
Cloud Functions currently supports Node.js, Python, Go, Java, .NET, and Ruby. The supported languages and versions are regularly updated by Google.
How does Google Cloud Functions handle scaling?
Cloud Functions automatically scales based on the number of incoming requests or events. Google Cloud manages the underlying infrastructure, ensuring that functions scale up or down to meet demand without requiring manual intervention.
What is the cost model for Google Cloud Functions?
Cloud Functions uses a pay-per-use pricing model. You are charged for the time your function runs, the resources it consumes (CPU, memory), and the number of invocations. There is a free tier available for a certain amount of usage each month.
How can I monitor the performance of my Cloud Functions?
Google Cloud provides built-in monitoring and logging capabilities through Cloud Logging and Cloud Monitoring. You can view logs, metrics, and set up alerts to monitor the performance and health of your functions.