The migration of petabyte-scale datasets to the cloud presents a formidable challenge, demanding meticulous planning and execution. This process involves a multifaceted approach, encompassing data assessment, infrastructure selection, secure transfer mechanisms, and ongoing management strategies. Successfully navigating this complex landscape requires a deep understanding of data formats, network optimization, security protocols, and cost-effective resource allocation. This document serves as a comprehensive guide, breaking down the critical steps and considerations involved in transferring vast amounts of data to the cloud, enabling organizations to leverage the scalability, agility, and cost benefits of cloud computing.
The journey begins with a thorough data inventory and profiling, ensuring data compatibility with cloud platforms. Next, selecting the appropriate cloud provider and services is crucial, considering factors such as data transfer costs, storage options, and compute capabilities. The choice of data transfer methods, ranging from online to offline approaches, must align with the specific dataset characteristics, network bandwidth limitations, and security requirements.
Data security and encryption are paramount throughout the migration, protecting sensitive information both in transit and at rest. Furthermore, network optimization, data integrity validation, and continuous monitoring are essential for a smooth and successful migration. This guide provides a structured framework to address these aspects, ensuring a reliable and efficient data transfer process.
Planning and Preparation for Petabyte-Scale Data Migration
Migrating petabytes of data to the cloud is a complex undertaking that requires meticulous planning and preparation. A poorly planned migration can lead to significant downtime, data loss, and increased costs. The initial phases of the migration process are crucial for ensuring a smooth and successful transition. These steps establish a solid foundation, mitigating risks and maximizing the efficiency of the migration effort.
Initial Steps Before Beginning a Petabyte-Scale Data Migration
The initial steps before beginning a petabyte-scale data migration involve a comprehensive assessment of the existing infrastructure, data characteristics, and business requirements. This foundational phase ensures that the subsequent migration activities are well-informed and aligned with the organization’s objectives.The following actions should be undertaken:* Define Migration Goals and Objectives: Clearly articulate the reasons for migrating to the cloud. Specify desired outcomes, such as cost reduction, improved scalability, enhanced disaster recovery, or improved performance.
Define key performance indicators (KPIs) to measure the success of the migration.
Assess Current Infrastructure
Conduct a thorough audit of the existing on-premises infrastructure, including servers, storage systems, network configurations, and security protocols. Document the hardware specifications, operating systems, applications, and dependencies.
Select a Cloud Provider
Evaluate different cloud providers based on their services, pricing models, security features, compliance certifications, and geographical regions. Consider factors such as data transfer costs, storage costs, and compute costs.
Develop a Migration Strategy
Determine the appropriate migration approach. This may include rehosting (lift and shift), refactoring, rearchitecting, or replacing applications. Consider the complexity, time, and cost associated with each approach.
Establish a Project Team
Assemble a dedicated project team with expertise in data migration, cloud technologies, networking, security, and project management. Define roles and responsibilities for each team member.
Create a Migration Plan
Develop a detailed migration plan that Artikels the scope, schedule, budget, resources, and risks associated with the migration. The plan should include specific tasks, milestones, and dependencies.
Obtain Stakeholder Buy-in
Secure approval and support from key stakeholders, including IT management, business users, and security teams. Communicate the benefits of the migration and address any concerns or questions.
Essential Resources Needed for the Migration Process
Successfully migrating petabytes of data to the cloud requires a strategic allocation of resources. These resources encompass personnel, hardware, and software, each playing a critical role in ensuring a smooth and efficient data transfer process.The essential resources needed include:* Personnel: A skilled and experienced team is crucial. This team should include:
Project Manager
Responsible for overseeing the entire migration project, managing timelines, and ensuring the project stays on track.
Cloud Architects
Experts in cloud technologies, responsible for designing and implementing the cloud infrastructure.
Data Migration Specialists
Specialists in data transfer techniques and tools. They ensure data integrity and efficient transfer.
Network Engineers
Manage network configurations and ensure sufficient bandwidth for data transfer.
Security Specialists
Responsible for securing the data during transit and at rest in the cloud.
Database Administrators
Manage and optimize database migrations.
Hardware
Adequate hardware resources are essential for both the source and destination environments.
Source Infrastructure
Sufficient compute and storage resources on-premises to handle the data extraction and transfer processes.
Network Connectivity
High-speed, reliable network connectivity, including sufficient bandwidth, to facilitate rapid data transfer to the cloud. Consider dedicated circuits or optimized network configurations.
Staging Area (Optional)
A temporary storage location, either on-premises or in the cloud, to stage the data before the final migration.
Software
The selection of appropriate software tools is crucial for data migration, monitoring, and management.
Data Migration Tools
Tools such as AWS DataSync, Azure Data Box, or Google Cloud Storage Transfer Service to facilitate data transfer.
Data Profiling Tools
Tools to analyze data characteristics, identify data quality issues, and understand data relationships.
Monitoring Tools
Tools to monitor the progress of the migration, track performance metrics, and identify any bottlenecks or issues.
Security Software
Encryption tools, access controls, and other security software to protect the data during transit and at rest.
The Importance of a Comprehensive Data Inventory and Data Profiling Before Migration
A comprehensive data inventory and data profiling are foundational activities that significantly enhance the efficiency and success of a petabyte-scale data migration. These processes provide critical insights into the data landscape, enabling informed decision-making and minimizing potential risks.Data inventory and data profiling include:* Data Inventory:
Identify and document all data sources, including databases, file systems, and applications.
Catalog data types, formats, and sizes.
Map data dependencies and relationships.
Document data ownership and access controls.
Data Profiling
Analyze data quality, including completeness, accuracy, consistency, and validity.
Identify data anomalies and inconsistencies.
Assess data volume and growth rates.
Determine data usage patterns.
Assess data sensitivity and regulatory compliance requirements.
These activities provide several key benefits:* Reduced Migration Time and Cost: Understanding the data landscape enables efficient data transfer strategies, minimizing downtime and resource consumption.
Improved Data Quality
Data profiling identifies data quality issues early in the process, allowing for data cleansing and remediation before migration.
Enhanced Security and Compliance
Data inventory and profiling help identify sensitive data and ensure compliance with relevant regulations.
Optimized Cloud Infrastructure
Insights into data characteristics enable the selection of the most appropriate cloud storage and compute resources.
Reduced Risk of Data Loss or Corruption
Comprehensive data assessment mitigates the risk of data loss or corruption during the migration process.
Data Storage Formats and Cloud Platform Compatibility
Selecting the appropriate data storage format is crucial for optimizing data migration and storage in the cloud. The compatibility of these formats with various cloud platforms is a critical consideration. The following table Artikels several common data storage formats and their compatibility across major cloud platforms.
| Data Storage Format | Description | AWS Compatibility | Azure Compatibility | Google Cloud Compatibility |
|---|---|---|---|---|
| CSV (Comma-Separated Values) | Plain text format for tabular data. | Fully compatible with services like S3, Redshift, and Athena. | Fully compatible with Blob Storage, Data Lake Storage, and Synapse Analytics. | Fully compatible with Cloud Storage, BigQuery, and Dataflow. |
| Parquet | Columnar storage format optimized for analytical queries. | Excellent compatibility with services like S3, Athena, and Redshift Spectrum. | Excellent compatibility with Data Lake Storage and Synapse Analytics. | Excellent compatibility with Cloud Storage, BigQuery, and Dataflow. |
| Avro | Row-based storage format designed for data serialization and exchange. | Good compatibility with S3 and services that support Hadoop ecosystems. | Good compatibility with Data Lake Storage and services that support Hadoop ecosystems. | Good compatibility with Cloud Storage and services that support Hadoop ecosystems. |
| JSON (JavaScript Object Notation) | Human-readable format for structured data. | Fully compatible with S3 and services like Athena and Glue. | Fully compatible with Blob Storage and Data Lake Storage. | Fully compatible with Cloud Storage and BigQuery. |
Choosing the Right Cloud Provider and Services
Selecting the appropriate cloud provider and services is a critical decision in petabyte-scale data migration, impacting cost, performance, security, and operational efficiency. A thorough evaluation of available options, considering the specific requirements of the data and the organization’s objectives, is paramount. This section provides a framework for making informed decisions in this crucial phase of the migration process.
Key Factors in Cloud Provider Selection
Several factors must be carefully evaluated when choosing a cloud provider for petabyte-scale data migration. These factors directly influence the success, cost-effectiveness, and long-term viability of the migration project.
- Data Volume and Velocity: The sheer volume of data (petabytes) and the rate at which it needs to be transferred (velocity) are primary drivers. Providers must offer services that can handle these scales efficiently. Consider the impact of network bandwidth limitations, data transfer protocols, and the need for parallelization to optimize transfer times. For example, AWS Snowball, Azure Data Box, and Google Transfer Appliance are designed to physically transport large datasets when network transfer is not feasible or cost-effective.
- Data Format and Structure: The format of the data (structured, semi-structured, or unstructured) and its organization within the source environment (e.g., relational databases, object storage) influence the choice of migration tools and services. Providers offer specialized services for different data types and sources. For instance, AWS Database Migration Service (DMS) is optimized for database migrations, while Azure Data Factory and Google Cloud Dataflow offer robust data integration and transformation capabilities.
- Geographic Location and Compliance Requirements: Data residency requirements, dictated by regulations like GDPR or HIPAA, are crucial. Providers must offer data centers in the necessary geographic regions to comply with these regulations. This necessitates understanding the provider’s global infrastructure, data center locations, and compliance certifications. Consider latency implications based on the location of the data source and destination.
- Security and Compliance: Data security is paramount. Evaluate the provider’s security measures, including encryption, access controls, and compliance certifications (e.g., SOC 2, ISO 27001). Ensure the provider offers tools and services to protect data during transit and at rest. Consider the provider’s incident response capabilities and their ability to meet specific industry compliance standards.
- Cost and Pricing Models: Analyze the pricing models for data transfer, storage, and compute resources. Understand the various cost components, including egress fees, storage costs, and the costs associated with specific migration services. Compare the pricing across providers, considering factors like data transfer volume, storage duration, and the use of managed services. Utilize cost optimization tools offered by each provider to estimate and manage migration expenses.
- Performance and Scalability: Assess the provider’s network performance, storage performance, and compute capabilities to ensure they meet the performance requirements of the migrated data and applications. The cloud provider must be able to scale resources up or down dynamically to handle fluctuations in data volume and workload demands. Consider the provider’s service level agreements (SLAs) for performance and availability.
- Migration Tools and Services: Evaluate the availability and capabilities of migration tools and services offered by each provider. These tools streamline the migration process, reduce manual effort, and improve efficiency. Consider factors such as the ease of use, the level of automation, and the support for different data sources and destinations.
- Vendor Lock-in and Portability: Consider the potential for vendor lock-in and the ability to migrate data and applications to another provider if needed. Evaluate the provider’s support for open standards, interoperability, and the availability of tools for data portability. Plan for a potential exit strategy and assess the cost and complexity of migrating away from the chosen provider.
Comparison of Data Migration Services: AWS, Azure, and Google Cloud
Each major cloud provider – AWS, Azure, and Google Cloud – offers a suite of data migration services tailored to different needs and scenarios. Understanding the strengths and weaknesses of each provider’s offerings is crucial for making an informed decision.
| Feature | AWS | Azure | Google Cloud |
|---|---|---|---|
| Data Transfer Services | AWS Snow Family (Snowball, Snowcone, Snowmobile), AWS DataSync, AWS Transfer Family, AWS Direct Connect | Azure Data Box (Disk, Appliance, Heavy), Azure Data Box Gateway, Azure Data Transfer service, Azure ExpressRoute | Google Transfer Appliance, Storage Transfer Service, Google Cloud Dedicated Interconnect |
| Data Migration Services | AWS Database Migration Service (DMS), AWS Schema Conversion Tool (SCT), AWS Application Migration Service (MGN) | Azure Database Migration Service (DMS), Azure Migrate | Google Cloud Database Migration Service, Google Cloud Storage Transfer Service |
| Storage Services | Amazon S3, Amazon Glacier, Amazon EBS, Amazon EFS | Azure Blob Storage, Azure Archive Storage, Azure Disk Storage, Azure Files | Google Cloud Storage, Google Cloud Storage Nearline, Google Cloud Persistent Disk, Google Cloud Filestore |
| Compute Services | Amazon EC2, AWS Lambda, Amazon ECS, Amazon EKS | Azure Virtual Machines, Azure Functions, Azure Container Instances, Azure Kubernetes Service | Google Compute Engine, Google Cloud Functions, Google Kubernetes Engine |
| Networking Services | Amazon VPC, AWS Direct Connect, Amazon CloudFront | Azure Virtual Network, Azure ExpressRoute, Azure CDN | Google Cloud Virtual Network, Google Cloud Interconnect, Google Cloud CDN |
| Key Strengths | Mature ecosystem, extensive service offerings, large market share, broad geographic reach. | Strong integration with Microsoft products, hybrid cloud capabilities, enterprise-focused solutions. | Innovative technologies, data analytics expertise, competitive pricing, global network. |
| Key Weaknesses | Complexity of service offerings, cost can be challenging to manage, vendor lock-in concerns. | Can be less cost-effective for certain workloads, limited geographic reach compared to AWS. | Smaller market share compared to AWS and Azure, some services are still evolving. |
Specific Cloud Services Required for Large-Scale Data Migration
Successful petabyte-scale data migration requires a combination of storage, compute, and networking services. The specific services chosen depend on the migration strategy and the characteristics of the data.
- Storage Services: Cloud storage provides the destination for the migrated data. Object storage services like Amazon S3, Azure Blob Storage, and Google Cloud Storage are often preferred for their scalability, durability, and cost-effectiveness. Consider the storage tiers offered by each provider (e.g., hot, cold, archive) to optimize costs based on data access frequency. For instance, infrequently accessed data can be stored in archive tiers to reduce storage costs.
- Compute Services: Compute resources are needed for data processing, transformation, and validation during the migration process. Virtual machines (e.g., Amazon EC2, Azure Virtual Machines, Google Compute Engine) or serverless compute services (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) can be used, depending on the workload. The choice depends on the processing requirements and the need for scalability and automation.
- Networking Services: Networking services are essential for data transfer. These include virtual private clouds (VPCs), virtual networks, and direct connections. Services like AWS Direct Connect, Azure ExpressRoute, and Google Cloud Dedicated Interconnect provide dedicated network connections for high-bandwidth data transfers. Content Delivery Networks (CDNs) like Amazon CloudFront, Azure CDN, and Google Cloud CDN can be used to accelerate data access from geographically dispersed locations.
- Data Transfer Services: Data transfer services are designed specifically for moving data to the cloud. This category includes physical data transfer devices (e.g., AWS Snowball, Azure Data Box, Google Transfer Appliance) for large datasets, as well as network-based transfer services like AWS DataSync, Azure Data Box Gateway, and Google Cloud Storage Transfer Service.
- Database Migration Services: If the migration involves databases, specialized services are often used to minimize downtime and ensure data integrity. Examples include AWS Database Migration Service (DMS), Azure Database Migration Service (DMS), and Google Cloud Database Migration Service. These services automate the migration process, handle schema conversion, and replicate data continuously.
- Data Integration and Transformation Services: For complex data transformations, data integration services are necessary. Examples include AWS Glue, Azure Data Factory, and Google Cloud Dataflow. These services provide capabilities for data extraction, transformation, and loading (ETL), enabling the preparation of data for analysis or other applications.
- Monitoring and Logging Services: Monitoring and logging services are crucial for tracking the progress of the migration, identifying issues, and ensuring data integrity. Examples include Amazon CloudWatch, Azure Monitor, and Google Cloud Operations Suite. These services provide insights into resource utilization, performance metrics, and error logs.
Pricing Models of Cloud Data Transfer Services
Understanding the pricing models of cloud data transfer services is essential for controlling migration costs. Each provider offers different pricing structures, including data transfer charges, storage costs, and fees for using specific migration tools.
- Data Transfer Ingress: Typically, data transfer
-into* the cloud is free of charge. However, there might be exceptions depending on the specific service and the region. - Data Transfer Egress: Data transfer
-out* of the cloud (egress) is usually charged. The pricing varies based on the destination (e.g., internet, another cloud provider, on-premises) and the region. The cost increases with the volume of data transferred. For example, AWS charges for data transfer out of Amazon S3, with the price varying based on the destination and the volume of data transferred. - Data Transfer within the Cloud: Transferring data between services within the same cloud provider may be free or have lower costs compared to egress. This is an important consideration when designing the migration architecture.
- Physical Data Transfer Devices: Services like AWS Snowball, Azure Data Box, and Google Transfer Appliance have associated costs. These often include a per-device fee, a daily storage fee, and data transfer fees. The total cost depends on the device capacity, the duration of use, and the amount of data transferred. The cost-effectiveness of these devices depends on the data volume, the network bandwidth, and the time required for data transfer.
For example, AWS Snowball has a fixed cost per device, plus a per-GB data transfer cost, while Azure Data Box offers various pricing tiers based on capacity and usage.
- Managed Data Transfer Services: Services like AWS DataSync, Azure Data Box Gateway, and Google Cloud Storage Transfer Service have pricing models that depend on the amount of data transferred, the duration of use, and the specific features utilized. Some services may also include a per-operation fee.
- Storage Costs: Storage costs are incurred for storing the data in the cloud. Pricing varies based on the storage tier (e.g., standard, infrequent access, archive) and the region. Higher tiers provide faster access but come with higher costs.
- Database Migration Service Fees: Database migration services (e.g., AWS DMS, Azure DMS, Google Cloud DMS) often have associated costs, which may be based on the number of database instances, the amount of data transferred, and the duration of the migration.
- Network Bandwidth Costs: Using dedicated network connections (e.g., AWS Direct Connect, Azure ExpressRoute, Google Cloud Interconnect) can incur monthly charges. These charges are often based on the bandwidth provisioned and the duration of the connection.
- Cost Optimization Tools: Cloud providers offer tools to help customers estimate and manage migration costs. These tools provide insights into resource utilization, cost trends, and optimization recommendations. Examples include AWS Cost Explorer, Azure Cost Management, and Google Cloud Pricing Calculator.
Data Transfer Methods and Techniques

Migrating petabytes of data to the cloud necessitates careful consideration of data transfer methods and techniques. The selection of the appropriate method hinges on factors such as network bandwidth, data volume, geographical distance, and the acceptable downtime. This section explores various data transfer methods, their step-by-step procedures, advantages, disadvantages, and practical implementation using specific tools.
Online Data Transfer Methods
Online data transfer methods involve moving data directly over a network connection. These methods are suitable when sufficient network bandwidth is available and the migration timeline is not severely constrained. The efficiency of online transfers is heavily influenced by network performance and the capabilities of the cloud provider’s ingestion endpoints.
Several online data transfer methods exist, each with specific characteristics:
- Network-Based Transfers: These methods use standard network protocols to move data.
- API-Based Transfers: Cloud providers often offer APIs to facilitate data ingestion, allowing for optimized transfer processes.
- Specialized Transfer Tools: Dedicated tools, often provided by cloud vendors, can improve transfer speeds and provide features like parallel uploads and data integrity checks.
A detailed procedure for online data transfer involves the following steps:
- Assessment of Network Bandwidth: Determine the available network bandwidth and estimate the transfer time based on the data volume. Consider using network monitoring tools to analyze the current bandwidth usage.
- Choosing the Right Transfer Tool: Select a transfer tool based on the cloud provider and the type of data. This could involve the provider’s native tools (e.g., AWS CLI, Azure AzCopy, Google Cloud Storage gsutil) or third-party solutions.
- Configuration and Setup: Configure the chosen tool with the necessary credentials (e.g., access keys, API tokens), source and destination paths, and any desired transfer parameters (e.g., concurrency, chunk size).
- Data Transfer Initiation: Start the data transfer process. Monitor the transfer progress and address any errors that may arise. Many tools provide real-time monitoring dashboards.
- Data Validation: Once the transfer is complete, validate the data integrity by comparing checksums or performing sample data checks.
The advantages and disadvantages of online data transfer methods for petabyte-scale migrations are:
- Advantages:
- Real-time data transfer, minimizing downtime.
- Suitable for incremental data migration, allowing for continuous data synchronization.
- No need for physical shipping of storage devices.
- Disadvantages:
- Heavily dependent on network bandwidth, which can be a bottleneck.
- Transfer times can be long, especially for large datasets and limited bandwidth.
- Network costs can be significant, particularly for egress traffic.
Offline Data Transfer Methods
Offline data transfer methods involve physically shipping storage devices containing the data to the cloud provider. These methods are useful when network bandwidth is limited or the data volume is too large for online transfer within an acceptable timeframe. Offline methods often utilize specialized devices designed for secure data transfer.
Offline data transfer typically involves these steps:
- Device Selection: Choose a suitable storage device provided by the cloud vendor (e.g., AWS Snowball, Azure Data Box). Consider factors such as storage capacity, security features, and transfer speed.
- Data Preparation: Prepare the data for transfer. This may involve data compression, encryption, and organization according to the cloud provider’s requirements.
- Data Transfer to Device: Transfer the data from the source to the physical storage device using the vendor-provided tools or utilities. Ensure data integrity during the transfer process.
- Device Shipping: Ship the storage device to the cloud provider’s data center. Follow the provider’s shipping guidelines to ensure secure and timely delivery.
- Data Ingestion: Once the device arrives at the data center, the cloud provider ingests the data into the cloud storage.
- Data Validation: Verify the data integrity after the ingestion process is complete. Compare checksums or perform sample data checks.
- Device Return (Optional): The storage device might be returned to the user or disposed of according to the cloud provider’s policy.
The advantages and disadvantages of offline data transfer methods for petabyte-scale migrations are:
- Advantages:
- Bypasses network bandwidth limitations.
- Faster transfer times compared to online methods, especially for large datasets.
- Suitable for environments with limited or unstable network connectivity.
- Disadvantages:
- Requires physical handling and shipping of storage devices.
- Introduces potential security risks during transit.
- Involves downtime for the shipping and ingestion process.
- Additional costs for device rental and shipping.
Configuring and Using AWS Snowball for Data Migration
AWS Snowball is a physical data transport solution that uses secure appliances to transfer large amounts of data into and out of AWS. It is a suitable option for petabyte-scale migrations where network bandwidth is a constraint.
Here’s a step-by-step guide to configuring and using AWS Snowball:
- AWS Account and IAM Permissions: Ensure you have an active AWS account and have configured the necessary IAM (Identity and Access Management) permissions to access Snowball services.
- Snowball Job Creation: In the AWS Management Console, create a Snowball job. Specify the source and destination S3 buckets, the desired Snowball device type (e.g., Snowball Edge), and the data transfer direction (import or export).
- Device Order and Configuration: Order the Snowball device. AWS will ship the device to your specified address. Follow the instructions provided to configure the device’s network settings and security credentials.
- Data Transfer to Snowball: Use the Snowball client or an S3 compatible tool to transfer data from your on-premises environment to the Snowball device. This involves:
- Installing the Snowball client on a host computer.
- Connecting the Snowball device to the host computer via a network cable.
- Using the Snowball client to unlock the device.
- Initiating the data transfer process.
Example: A company, “DataCorp,” needed to migrate 500 TB of video archive data to AWS. Their network bandwidth was limited to 100 Mbps. Estimating the online transfer time, it would take approximately 120 days. Using AWS Snowball Edge, they were able to transfer the data in less than a week, including the time for data transfer to the device, shipping, and ingestion.
Data Security and Encryption During Migration
Data security and encryption are paramount during petabyte-scale data migrations. The sheer volume of data, combined with the extended transfer durations, increases the attack surface and the potential for data breaches. Compromised data can lead to significant financial losses, reputational damage, and legal ramifications. Implementing robust security measures throughout the migration process is therefore crucial to protect sensitive information and maintain data integrity.
Encryption, both in transit and at rest, is a fundamental component of a comprehensive security strategy.
Implementing Encryption in Transit and at Rest
Data encryption, in transit and at rest, ensures confidentiality and protects data from unauthorized access during the migration process. Encryption in transit secures data while it’s being transferred across networks, preventing eavesdropping and data interception. Encryption at rest protects data stored in cloud storage, rendering it unreadable without the appropriate decryption keys, even if unauthorized access to the storage occurs.To implement encryption in transit, several methods are available:
- Transport Layer Security (TLS/SSL): TLS/SSL provides secure communication channels by encrypting data transmitted between the source and destination. It’s widely used for web traffic and offers robust security. The implementation involves configuring TLS/SSL certificates on both the source and destination systems, ensuring that all data transfers occur over encrypted connections. For example, when using the `rsync` command for data transfer, you can use the `-e ssh` option, which leverages SSH for encrypted communication, using TLS/SSL.
This encrypts the data stream, preventing unauthorized access during transit.
- Virtual Private Networks (VPNs): VPNs create encrypted tunnels over public networks, such as the internet. All data transmitted through the VPN tunnel is encrypted, providing a secure connection. This is particularly useful when transferring data across untrusted networks. Configuring a VPN involves establishing a secure connection between the source and destination, encapsulating all data within an encrypted tunnel. Using a VPN ensures that all data traffic, including file transfers, is protected by encryption.
- Encrypted Protocols (e.g., SFTP, HTTPS): Protocols like SFTP (Secure File Transfer Protocol) and HTTPS (Hypertext Transfer Protocol Secure) inherently encrypt data during transfer. SFTP uses SSH to provide a secure channel for file transfers, while HTTPS uses TLS/SSL to encrypt web traffic. Utilizing these protocols simplifies the implementation of encryption. When migrating data using SFTP, the file transfer process is automatically encrypted.
This ensures the confidentiality of the data as it moves between the source and destination.
Encryption at rest protects data stored in the cloud. This typically involves encrypting the data before it is uploaded to the cloud storage service or using the cloud provider’s encryption features.
- Client-Side Encryption: Data is encrypted on the source system before being transferred to the cloud. The encryption keys are managed by the data owner. This provides greater control over the encryption process. For example, using a tool like `gpg` (GNU Privacy Guard) to encrypt files before uploading them to cloud storage. The data is encrypted locally using a specified key, and only authorized users with the corresponding decryption key can access the data.
- Server-Side Encryption: The cloud provider encrypts the data at rest, using keys managed by the provider or the customer. This simplifies the implementation process, as the encryption is handled by the cloud provider. For example, many cloud providers offer server-side encryption with customer-managed keys (SSE-C). This allows users to upload their data to the cloud, and the cloud provider encrypts it using a key managed by the user.
The user retains control over the key and the ability to decrypt the data.
Best Practices for Secure Encryption Key Management
Secure key management is critical to maintaining the confidentiality of encrypted data. Compromised keys can render encryption useless.Key management involves the following:
- Key Generation: Keys should be generated using strong, cryptographically secure random number generators. Avoid using weak or predictable keys. The length of the key is a critical factor. For example, using a 256-bit Advanced Encryption Standard (AES) key provides a much higher level of security than a 128-bit key.
- Key Storage: Keys should be stored securely, using dedicated key management systems (KMS), hardware security modules (HSMs), or other secure storage mechanisms. Avoid storing keys alongside the encrypted data. Using a KMS, such as AWS KMS or Azure Key Vault, allows for centralized management and secure storage of encryption keys. HSMs provide a high level of security, as the keys are stored and processed within a tamper-resistant hardware device.
- Key Rotation: Regularly rotate encryption keys to reduce the impact of a potential key compromise. Key rotation involves generating new keys and re-encrypting the data. For example, implementing a key rotation policy where encryption keys are changed every 90 days. This ensures that even if a key is compromised, the attacker only has access to the data encrypted with that key for a limited time.
- Access Control: Implement strict access control policies to limit who can access and manage encryption keys. Use role-based access control (RBAC) to define specific permissions for different users. For example, granting only authorized security administrators access to manage encryption keys within a KMS. This minimizes the risk of unauthorized access to the keys.
- Key Revocation: Have a process for revoking compromised keys or keys associated with compromised accounts. Revocation immediately prevents access to encrypted data. For example, if an employee leaves the company, their access to encryption keys should be revoked immediately to prevent potential data breaches.
Encryption Algorithms and Security Levels
The selection of an appropriate encryption algorithm is essential for data security. Different algorithms offer varying levels of security. The choice of algorithm should consider the sensitivity of the data and the regulatory requirements.
| Encryption Algorithm | Key Length (bits) | Security Level |
|---|---|---|
| Advanced Encryption Standard (AES) | 128, 192, 256 | High |
| Triple DES (3DES) | 168 | Medium (becoming outdated) |
| Rivest–Shamir–Adleman (RSA) | 2048, 4096+ | High (for key exchange and digital signatures) |
The AES algorithm is a widely adopted standard, offering robust security with key lengths of 128, 192, or 256 bits. RSA is commonly used for key exchange and digital signatures, providing a high level of security with longer key lengths. Triple DES (3DES) is an older algorithm that is less secure than AES and is generally not recommended for new implementations.
It’s crucial to select an algorithm with sufficient key length and security to protect the data. For instance, migrating highly sensitive financial data would necessitate using AES with a 256-bit key, or equivalent or greater security levels, to meet regulatory compliance and protect against sophisticated attacks.
Network Considerations and Optimization
Network performance is a critical factor in the successful and timely migration of petabytes of data to the cloud. The network infrastructure must be robust and optimized to handle the substantial data transfer volumes and maintain acceptable transfer speeds. Inefficient network configurations can lead to bottlenecks, increased migration times, and higher costs.
Network Bandwidth Requirements
The determination of adequate network bandwidth is paramount when planning petabyte-scale data migrations. This calculation directly impacts the duration of the migration process and the overall cost.To estimate bandwidth needs, several factors must be considered:
- Data Volume: The total amount of data to be transferred, measured in petabytes (PB), is the primary driver.
- Desired Migration Time: Define the acceptable timeframe for completion. This is often influenced by business requirements and service level agreements (SLAs).
- Network Availability: The consistent and reliable network uptime throughout the migration period is essential. Downtime can significantly impact the migration timeline.
- Network Overhead: Consider the overhead associated with data transfer protocols, encryption, and other network processes. This can add to the overall bandwidth requirements.
The fundamental formula for calculating the required bandwidth is:
Bandwidth = (Data Volume / Desired Migration Time) + Overhead
For example, migrating 10 PB of data in 30 days requires a specific bandwidth capacity. If the overhead is estimated at 10%, then the bandwidth calculation needs to account for this additional data. The resulting bandwidth requirement can then be translated into the necessary network infrastructure, including internet connections, and network switches. In scenarios where migration timelines are highly constrained, higher bandwidth connections, such as dedicated 10 Gbps or even 100 Gbps links, might be necessary.
Companies like Netflix, for instance, regularly migrate massive datasets, and they require significant bandwidth to maintain content delivery and data processing operations.
Strategies for Optimizing Network Performance
Optimizing network performance is crucial for maximizing data transfer speeds and minimizing migration times. Several strategies can be employed to improve network efficiency during the migration process.Network optimization strategies include:
- Bandwidth Aggregation: Utilizing multiple network connections in parallel to increase the total available bandwidth. This can be achieved through technologies like Link Aggregation Control Protocol (LACP).
- Traffic Shaping: Prioritizing data transfer traffic over other network activities to ensure sufficient bandwidth allocation.
- TCP Optimization: Fine-tuning TCP parameters, such as window size and buffer size, to improve data throughput.
- Network Monitoring: Continuously monitoring network performance to identify and address bottlenecks.
- Choosing Optimal Transfer Protocols: Selecting data transfer protocols (e.g., TCP, UDP) and implementing appropriate configurations to maximize throughput.
An example of bandwidth aggregation is using multiple 1 Gbps connections to effectively achieve a higher aggregate bandwidth, such as 2 Gbps or 3 Gbps, depending on the number of connections used. Traffic shaping can be used to ensure that data migration traffic is prioritized over other network traffic, preventing interference from other applications or services. Network monitoring tools can provide real-time insights into network performance, enabling proactive identification and resolution of potential issues that may arise during the data transfer.
These tools can alert administrators to any performance degradation or bottlenecks that may need to be addressed to maintain optimal transfer speeds.
Role of WAN Optimization Techniques
WAN (Wide Area Network) optimization techniques play a vital role in accelerating data migration, particularly when data must traverse long distances or networks with limited bandwidth. These techniques address the challenges of transferring large datasets across geographically dispersed locations.WAN optimization encompasses several techniques:
- Data Compression: Compressing data before transmission to reduce the amount of data that needs to be transferred.
- Deduplication: Identifying and eliminating redundant data blocks to avoid transmitting the same data multiple times.
- Caching: Caching frequently accessed data on the receiving end to reduce the need for repeated transfers.
- Protocol Optimization: Optimizing network protocols to improve efficiency and reduce overhead.
For instance, data compression can reduce the size of data by up to 50% or more, depending on the data type and compression algorithm used. Deduplication can significantly reduce the volume of data transferred by identifying and eliminating redundant data blocks, especially in cases where data has been previously transferred. Caching techniques can store frequently accessed data locally, reducing the need for repeated transfers over the WAN.
These optimization techniques can be implemented using specialized hardware or software solutions, such as WAN optimization appliances. These solutions are often deployed at both the sending and receiving ends of the data transfer, and they can provide substantial performance improvements. Companies with geographically dispersed data centers often rely on WAN optimization to ensure that data migration is completed in a timely and cost-effective manner.
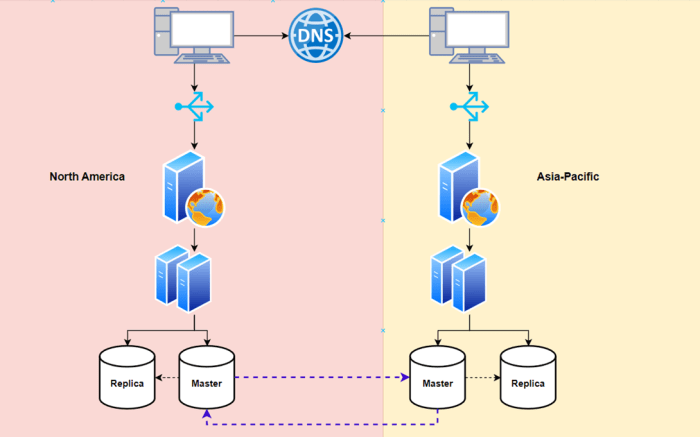
Network Architecture for High-Speed Data Transfer
The network architecture required for high-speed data transfer during petabyte-scale data migration is a critical design element. This architecture must be designed to accommodate the large data volumes and maintain optimal transfer speeds.A typical network architecture for high-speed data transfer involves several key components:
- High-Bandwidth Internet Connection: A dedicated and high-capacity internet connection is essential. This could be a 10 Gbps or 100 Gbps fiber optic connection, depending on the bandwidth requirements.
- Network Switches: High-performance network switches with sufficient port density and bandwidth capacity.
- WAN Optimization Appliances (if applicable): These appliances are used to optimize data transfer across the WAN.
- Data Transfer Servers: Servers optimized for data transfer, with sufficient processing power, memory, and storage capacity.
- Security Infrastructure: Firewall and intrusion detection systems to protect the data during transfer.
The diagram illustrates a typical network architecture for high-speed data transfer:
+-----------------------+ | Internet (10 Gbps+) | +---------+-----------+ | +---------v-----------+ | Core Router/Switch | +---------+-----------+ | +---------v-----------+ | Firewall/Security | +---------+-----------+ | +-------------------+-------+-------+-------------------+ | WAN Optimization | | | WAN Optimization | | Appliance (Sender)| | | Appliance (Receiver)| +--------+----------+ | +----------+--------+ | | | +--------v----------+ | +----------v--------+ | Data Transfer Server |-------|-------| Data Transfer Server | | (Source) | | | (Destination) | +-------------------+ | +-------------------+ | +---------v-----------+ | Local Network | +-----------------------+
The diagram depicts the sender’s network, the wide-area network, and the receiver’s network.
The sender’s data transfer server is connected to the WAN optimization appliance, which then connects to the high-bandwidth internet connection. On the receiver’s side, the WAN optimization appliance is connected to the data transfer server. The data travels from the source data transfer server, through the sender’s WAN optimization appliance, across the high-speed internet connection, through the receiver’s WAN optimization appliance, and finally to the destination data transfer server.
The firewall is positioned before the WAN optimization appliances to protect the network. The network switches and routers ensure efficient data routing. This architecture ensures a robust and secure high-speed data transfer environment.
Data Integrity and Validation
Ensuring data integrity is paramount during petabyte-scale cloud migrations. This involves verifying that data remains unchanged throughout the transfer process and that the data received in the cloud matches the source data. Implementing robust validation procedures is critical to minimize data loss, corruption, and discrepancies, ultimately guaranteeing the reliability and usability of the migrated data. Failure to properly validate data can lead to significant operational challenges and potentially compromise business decisions based on inaccurate information.
Methods for Ensuring Data Integrity During Migration
Data integrity during migration relies on a multi-faceted approach. These methods work in concert to minimize data corruption and ensure a successful migration.
- Checksum Verification: Checksums are calculated for the source data before migration. After the data is transferred, checksums are recalculated on the destination data. The two sets of checksums are then compared to verify data integrity. Popular checksum algorithms include MD5, SHA-1, and SHA-256. SHA-256 is often preferred due to its greater resistance to collision attacks.
- Hashing Algorithms: Hashing algorithms, like those used for checksums, generate a unique fingerprint of the data. These algorithms are used to detect any changes made to the data during transit or storage. The hash of the original data is compared with the hash of the migrated data.
- Metadata Synchronization: Metadata, including timestamps, file sizes, and access permissions, is crucial for data context. This metadata is migrated along with the data and then validated post-migration to ensure that it has been correctly transferred. Tools and scripts are employed to reconcile the metadata between the source and destination environments.
- Data Sampling: A representative sample of the data is selected and migrated. This sample is then thoroughly validated to assess the integrity of the overall dataset. This method is particularly useful for large datasets where validating every single data point would be time-consuming and resource-intensive. The sample size is often determined using statistical methods to ensure a sufficient level of confidence in the results.
- Bit-by-Bit Comparison: For critical data, a bit-by-bit comparison can be performed. This involves comparing the data in the source and destination environments at the lowest level. This is the most rigorous method for ensuring data integrity, but it can be very time-consuming and requires specialized tools.
- Transaction Logging and Auditing: Implement logging and auditing mechanisms throughout the migration process. These logs track all data transfers, modifications, and validation steps. This provides a detailed audit trail for troubleshooting and forensic analysis in case of data integrity issues.
Procedure for Validating Data After Migration
Validating data after migration involves a systematic process to verify that the migrated data is complete, accurate, and consistent with the original data.
- Checksum Verification: Calculate checksums for the migrated data using the same algorithm used during the initial verification. Compare these checksums with the checksums generated before migration.
- Data Comparison: Perform a direct comparison of a representative sample of data files or records from the source and destination environments. This comparison can involve comparing individual data fields, checking for data completeness, and verifying data relationships.
- Metadata Validation: Verify the consistency and accuracy of metadata, including timestamps, file sizes, and permissions, between the source and destination environments. This validation can involve using scripts to compare metadata attributes or employing automated tools to detect inconsistencies.
- Functional Testing: Conduct functional tests on the migrated data to ensure that it can be used as intended. This testing can involve executing queries, running reports, and verifying that data-driven applications function correctly.
- User Acceptance Testing (UAT): Involve end-users in the validation process by having them review and validate the migrated data. This is particularly important for business-critical data, as it allows users to verify the accuracy and usability of the data in their specific context.
- Performance Testing: Ensure the migrated data performs as expected within the cloud environment. This includes assessing query response times, data access speeds, and the overall performance of data-driven applications.
- Automated Validation: Automate the data validation process using scripts and tools to streamline the validation process and reduce the risk of human error. Automating these checks ensures they are consistently performed and can be easily repeated after subsequent migrations or data updates.
Techniques for Detecting and Resolving Data Corruption Issues
Detecting and resolving data corruption issues is critical for ensuring the reliability and usability of migrated data. This requires a combination of proactive measures and reactive troubleshooting techniques.
- Error Detection and Correction Codes (EDC/ECC): Employ EDC/ECC mechanisms during data transfer. These codes add redundant data to the original data, enabling the detection and correction of errors that may occur during transmission or storage.
- Data Replication: Replicate data across multiple storage locations within the cloud environment. This provides redundancy and ensures data availability even if a corruption issue occurs in one location.
- Data Scrubbing: Regularly scan data for corruption issues and automatically repair or replace corrupted data. Data scrubbing involves verifying data integrity by comparing checksums, verifying data against defined rules, and identifying any inconsistencies.
- Version Control: Implement version control mechanisms to track changes to the data and enable rollback to previous versions if corruption is detected. Version control can be crucial for quickly recovering from data corruption issues.
- Data Backup and Recovery: Establish a comprehensive data backup and recovery strategy. Regularly back up the migrated data to a separate location. In case of data corruption, use the backup to restore the data to a known good state.
- Logging and Monitoring: Implement robust logging and monitoring to track any errors or anomalies during data migration and storage. These logs can be used to identify the root cause of data corruption issues and implement corrective actions.
- Data Repair Tools: Utilize specialized data repair tools to automatically identify and repair corrupted data. These tools can use various techniques, such as checksum verification, data reconstruction, and data cleansing, to restore the data to a consistent state.
- Isolation and Investigation: When corruption is detected, isolate the affected data to prevent further damage. Conduct a thorough investigation to determine the root cause of the corruption and implement preventative measures.
Data Validation Tools and Functionalities
Numerous tools are available to facilitate data validation during and after the migration process. These tools automate many of the validation steps, reduce the risk of errors, and significantly speed up the overall process.
- Checksum Utilities: Tools like `md5sum`, `sha256sum`, and `openssl` are command-line utilities that generate and verify checksums for files. They are essential for confirming data integrity during transfer and storage. For example, using `sha256sum filename.txt` generates a SHA-256 hash of the file.
- Data Comparison Tools: Tools like `diff` and `cmp` (Unix/Linux) and specialized data comparison software, compare files or data sets, identifying differences between the source and destination data. These tools are valuable for validating the consistency of migrated data.
- Data Profiling Tools: Tools like Apache Griffin and AWS Glue DataBrew analyze data, providing insights into data quality, identifying inconsistencies, and profiling data characteristics. These tools help in understanding the data structure and identifying potential issues before and after migration.
- Database Validation Tools: Database-specific tools, such as `dbcc checkdb` (SQL Server) and `validate` (PostgreSQL), check the integrity of database structures and data. These tools are crucial for validating the integrity of database migrations.
- ETL (Extract, Transform, Load) Tools: ETL tools, like Apache NiFi, Informatica, and AWS Glue, include built-in data validation features, allowing for data quality checks during the transformation and loading processes. They can also perform checksum calculations and data comparisons.
- Data Quality Tools: Tools like IBM InfoSphere Information Analyzer and Trifacta Wrangler offer advanced data quality features, including data cleansing, profiling, and validation rules. These tools help ensure data accuracy and consistency.
- Custom Scripting: Using scripting languages like Python or Bash allows for the creation of customized validation scripts tailored to specific data structures and validation requirements. This allows for very specific checks and can be integrated into automated validation pipelines.
- Cloud Provider-Specific Tools: Cloud providers offer tools such as AWS DataSync, Google Cloud Storage Transfer Service, and Azure Data Box, that provide built-in data validation features and assist in the migration process. These services often include checksum verification and automated data integrity checks.
Monitoring and Progress Tracking

Effective monitoring is crucial for the successful migration of petabytes of data to the cloud. It provides real-time visibility into the migration process, allowing for proactive identification and resolution of issues. Without robust monitoring, organizations risk prolonged migration times, data loss, and unexpected costs. This section details the essential aspects of monitoring, including tool setup, alert interpretation, and dashboard design.
Importance of Data Migration Progress Monitoring
Monitoring the data migration progress is essential for several key reasons. It provides real-time insights into the performance of the migration, enabling timely interventions to address any bottlenecks or errors that may arise.
- Real-time Visibility: Monitoring tools provide a continuous stream of data, offering a comprehensive view of the migration’s progress, including transfer speeds, error rates, and overall completion percentage. This allows for immediate identification of any deviations from the expected performance.
- Error Detection and Resolution: Monitoring systems are designed to detect errors during data transfer. Early detection allows for swift troubleshooting and prevents data corruption or loss. The faster errors are detected, the less impact they have on the overall migration timeline.
- Performance Optimization: By tracking transfer speeds and identifying bottlenecks, monitoring helps in optimizing the migration process. This might involve adjusting network configurations, modifying data transfer methods, or scaling up resources to improve performance.
- Cost Management: Monitoring enables organizations to track the costs associated with data transfer and storage. It helps identify inefficiencies that may lead to unnecessary expenses and allows for optimization of resource allocation.
- Compliance and Reporting: Monitoring provides the data needed for compliance reporting and auditing. It ensures that the migration process adheres to the necessary regulations and standards, documenting all relevant aspects of the data transfer.
Setting Up Monitoring Tools
Setting up effective monitoring requires careful selection and configuration of appropriate tools. The chosen tools should be capable of tracking key metrics, generating alerts, and providing insightful visualizations.
- Choosing Monitoring Tools: Select tools that are compatible with the chosen cloud provider and data transfer methods. Consider using cloud-native monitoring services offered by the cloud provider (e.g., AWS CloudWatch, Azure Monitor, Google Cloud Monitoring) or third-party tools. Evaluate tools based on their ability to monitor the following metrics:
- Transfer Speeds: Monitor the rate at which data is being transferred, typically measured in gigabytes per second (GB/s) or terabytes per hour (TB/h).
- Error Rates: Track the number and types of errors encountered during data transfer, such as failed transfers, checksum errors, or network issues.
- Data Transfer Volume: Monitor the total amount of data transferred, the remaining data to be transferred, and the overall completion percentage.
- Resource Utilization: Monitor resource usage, such as network bandwidth, CPU utilization, and storage I/O, to identify any performance bottlenecks.
- Cost Metrics: Track the costs associated with data transfer, storage, and compute resources used during the migration process.
- Tool Configuration: Configure the selected monitoring tools to collect and analyze the relevant metrics. This involves setting up data sources, defining thresholds, and configuring alerts.
- Agent Installation: Install monitoring agents on the source and destination systems to collect data.
- Metric Configuration: Configure the tools to collect specific metrics, such as transfer speeds, error rates, and resource utilization.
- Alerting Setup: Configure alerts to be triggered when specific thresholds are exceeded. For example, set an alert to be triggered if the transfer speed drops below a certain level or if the error rate exceeds a predefined threshold.
- Integration: Integrate the monitoring tools with other systems, such as notification services (e.g., email, SMS, Slack) and incident management systems. This ensures that alerts are promptly delivered to the appropriate teams and that issues are addressed quickly.
Interpreting and Responding to Alerts
Understanding and responding to alerts generated during the migration process is crucial for maintaining data integrity and minimizing downtime. Alerts should be configured to provide timely notifications about critical events.
- Alert Types:
- High Error Rates: Indicates potential issues with data integrity or network connectivity. Investigate the error logs to determine the root cause and take corrective action.
- Low Transfer Speeds: Suggests bottlenecks in the network, storage, or data transfer process. Review network configurations, optimize data transfer methods, or scale up resources.
- High Resource Utilization: Indicates that resources are being overutilized, which can impact performance. Scale up resources or optimize resource allocation.
- Data Transfer Failures: Signifies critical issues that require immediate attention. Review the logs and take necessary actions to recover the failed transfers.
- Alert Response Procedures: Develop and document clear procedures for responding to different types of alerts. These procedures should include steps for investigating the issue, escalating the alert to the appropriate team, and implementing corrective actions.
- Troubleshooting Techniques:
- Review Logs: Analyze the logs generated by the data transfer tools to identify the root cause of the issue.
- Check Network Connectivity: Verify network connectivity between the source and destination systems.
- Test Data Transfer: Conduct a test data transfer to isolate the problem.
- Consult Documentation: Refer to the documentation for the data transfer tools and cloud provider services for troubleshooting guidance.
Dashboard Visualization for Real-Time Monitoring
A well-designed dashboard provides a centralized view of the migration’s progress, allowing for quick identification of issues and informed decision-making. The dashboard should display key metrics in an easy-to-understand format.
Dashboard Design:
A real-time monitoring dashboard should incorporate the following elements:
- Overview Section: Display key performance indicators (KPIs) at a glance, such as overall completion percentage, total data transferred, and estimated time remaining. This section provides a high-level view of the migration’s progress.
- Transfer Speed Charts: Display real-time charts showing data transfer speeds over time. This allows for identifying trends and potential bottlenecks. These charts might show transfer speeds for individual files, directories, or the entire migration.
- Error Rate Graphs: Present error rates over time, broken down by error type. This helps to quickly identify patterns and trends in errors. The graph should clearly indicate the number of errors and the time they occurred.
- Resource Utilization Metrics: Display resource utilization metrics, such as network bandwidth usage, CPU utilization, and storage I/O. This allows for identifying performance bottlenecks related to resource constraints.
- Alert Status Indicators: Clearly display the status of active alerts, including the alert type, severity, and affected component. This ensures that any critical issues are immediately visible.
- Interactive Elements: Include interactive elements, such as drill-down capabilities, to allow users to explore the data in more detail. This enables users to investigate specific issues and understand their root causes.
Example Dashboard Metrics and Visualization:
The following is a hypothetical example of a real-time monitoring dashboard. It illustrates the metrics that should be displayed and how they might be visualized.
Dashboard Example
| Metric | Visualization | Description |
|---|---|---|
| Overall Completion | Progress Bar | Displays the overall percentage of data migrated. |
| Total Data Transferred | Gauge Chart | Shows the total amount of data migrated, in terabytes (TB). |
| Estimated Time Remaining | Text Display | Provides an estimated time until the migration is complete. |
| Transfer Speed | Line Chart | Displays the data transfer speed over time, measured in GB/s or TB/h. |
| Error Rate | Bar Chart | Shows the number of errors encountered, categorized by error type. |
| Network Bandwidth Usage | Line Chart | Displays network bandwidth usage on both the source and destination sides. |
| CPU Utilization | Gauge Chart | Shows the CPU utilization of the servers involved in the migration. |
| Alert Status | Alert Table | Lists all active alerts, their severity, and affected components. |
Dashboard Benefits:
- Proactive Issue Identification: Real-time data visualization enables quick identification of issues and bottlenecks.
- Data-Driven Decision Making: The dashboard provides the data necessary to make informed decisions about the migration process.
- Improved Efficiency: By tracking performance metrics, the dashboard helps optimize the migration process.
- Enhanced Communication: The dashboard provides a shared view of the migration’s progress, facilitating communication among stakeholders.
Cost Optimization Strategies
Migrating petabytes of data to the cloud presents significant cost considerations. Effective cost optimization is crucial to ensure a successful and economically viable migration. This section delves into the various cost components, strategies for minimization, and practical techniques to manage expenses during large-scale data transfers.
Cost Components of Cloud Data Migration
Understanding the cost structure is the first step in optimizing cloud migration expenses. These costs are multifaceted and vary depending on the chosen cloud provider, services utilized, and the specifics of the data being migrated.
- Data Transfer Costs (Egress and Ingress): This is the cost associated with moving data into and out of the cloud. Ingress, the cost of bringing data
-into* the cloud, is often free or very low cost. Egress, the cost of retrieving data
-from* the cloud, is typically more expensive and a significant factor, especially for frequent data access. - Storage Costs: Cloud providers offer various storage tiers, each with different pricing models based on performance, availability, and access frequency. Selecting the appropriate tier for your data lifecycle is essential. Hot storage is optimized for frequently accessed data, while cold storage is for infrequently accessed archives, each with different pricing.
- Compute Costs: If data transformation or processing is performed during migration, compute resources (virtual machines, serverless functions) incur costs based on usage.
- Service-Specific Costs: Depending on the services used (e.g., database migration services, data replication tools), there may be additional charges based on the volume of data processed, the duration of service usage, or the number of operations performed.
- Network Costs: These costs are related to the network infrastructure used for data transfer, including bandwidth usage and any associated charges for specific network services.
- Operational Costs: These costs include the personnel and tools needed to manage and monitor the migration process.
Strategies for Optimizing Data Migration Costs
Cost optimization requires a strategic approach. Several techniques can significantly reduce migration expenses without compromising data integrity or transfer speed.
- Right-Sizing Services: Carefully assess your data storage and compute needs. Choose services and instance types that match your requirements to avoid over-provisioning and unnecessary costs.
- Data Tiering and Lifecycle Management: Implement data lifecycle policies to move data between storage tiers based on access frequency. Data accessed frequently should reside in hot storage, while less frequently accessed data should be moved to cheaper cold or archive storage.
- Data Compression and Deduplication: Compressing data before migration reduces the volume of data transferred, thus lowering data transfer costs. Deduplication eliminates redundant data, further minimizing the transfer volume and storage requirements.
- Scheduling Transfers: Schedule data transfers during off-peak hours or when network bandwidth is less expensive to leverage lower pricing tiers. Some cloud providers offer discounted rates for data transfers during certain times.
- Choosing the Right Data Transfer Method: Select the most cost-effective data transfer method based on data volume, network bandwidth, and time constraints. Consider using offline data transfer services (e.g., physical appliances) for very large datasets to minimize network charges.
- Leveraging Reserved Instances/Commitments: If you anticipate consistent resource usage, consider committing to a certain level of resource usage for a specific period to obtain discounted pricing.
- Monitoring and Optimization: Continuously monitor your cloud spending and optimize your resource usage. Utilize cost management tools provided by your cloud provider to identify areas for improvement.
Cost-Saving Techniques for Large-Scale Data Transfers
Practical examples of cost-saving techniques highlight the effectiveness of optimization strategies.
- Bulk Data Transfer Appliances: For petabyte-scale migrations, using physical appliances (e.g., AWS Snowball, Google Transfer Appliance, Azure Data Box) to transport data can significantly reduce egress charges, especially when network bandwidth is limited or expensive. These appliances are shipped to your location, data is loaded onto them, and then they are shipped back to the cloud provider for data ingestion.
- Data Compression before Transfer: Using tools like `gzip` or `7zip` can significantly reduce the size of data before transferring it to the cloud. For example, compressing a 100TB dataset with a 50% compression ratio would reduce the transfer volume to 50TB, cutting data transfer costs by half.
- Parallel Transfers: Utilizing multiple concurrent data transfer processes can increase transfer speeds and reduce the overall time spent on migration. Some cloud providers offer tools and services to facilitate parallel data transfers.
- Automated Data Tiering Policies: Implementing automated data tiering policies can move infrequently accessed data to lower-cost storage tiers. For example, data older than 90 days can be automatically moved from hot storage to cold storage, reducing storage costs.
- Optimized Network Configuration: Using network optimization techniques like Quality of Service (QoS) can prioritize data transfer traffic, and using direct connect or peering services can reduce network latency and costs.
Cloud Storage Tier Pricing Comparison
This table provides a comparative overview of pricing models for different cloud storage tiers offered by major cloud providers. Note that pricing can vary based on region, data volume, and other factors. The examples are illustrative and should not be considered as absolute pricing figures.
| Storage Tier | Typical Use Case | Pricing Model (per GB/month) | Key Features |
|---|---|---|---|
| Hot Storage (e.g., AWS S3 Standard, Azure Blob Storage Hot, Google Cloud Storage Standard) | Frequently accessed data, active workloads, application data | $0.023 – $0.025 | High availability, low latency, frequent data access, optimized for performance |
| Cool Storage (e.g., AWS S3 Intelligent-Tiering, Azure Blob Storage Cool, Google Cloud Storage Nearline) | Infrequently accessed data, backup and disaster recovery, data accessed once a month or less | $0.012 – $0.015 | Lower cost than hot storage, slightly higher retrieval latency, ideal for archival data |
| Cold/Archive Storage (e.g., AWS S3 Glacier, Azure Blob Storage Archive, Google Cloud Storage Coldline/Archive) | Data archives, long-term backups, data rarely accessed, regulatory compliance | $0.004 – $0.005 | Lowest cost, high retrieval latency (hours), suitable for infrequently accessed archives |
Data Transformation and Compatibility
Migrating petabytes of data to the cloud often necessitates data transformation to ensure seamless integration with the target environment. This process involves modifying data formats, structures, and content to align with the cloud platform’s requirements and optimize its usability. Successful transformation is crucial for maintaining data integrity, performance, and accessibility after migration.
Need for Data Transformation
Data transformation becomes essential when migrating data to the cloud due to inherent differences between on-premises systems and cloud platforms. These differences may include variations in data formats, database schemas, character encodings, and application-specific data models. Without proper transformation, data may become inaccessible, corrupted, or incompatible with cloud-based applications and services.
Common Data Transformation Tasks
Several common data transformation tasks are frequently performed during petabyte-scale data migrations.
- Format Conversion: This involves converting data from one format to another. Examples include converting CSV files to Parquet, JSON to Avro, or proprietary formats to standard formats supported by the cloud platform.
- Schema Mapping and Transformation: This addresses differences in database schemas between source and target systems. It may involve renaming columns, changing data types, restructuring tables, and consolidating or splitting data across different tables.
- Data Cleansing and Standardization: This involves identifying and correcting inconsistencies, errors, and inaccuracies in the data. Tasks include removing duplicate records, handling missing values, standardizing address formats, and validating data against predefined rules.
- Data Enrichment: This process adds extra information to the dataset to enhance its value. This may include adding geo-location data, populating missing fields, or adding contextual information to data points.
- Data Aggregation and Summarization: Transforming detailed data into summarized formats can improve performance and reduce storage costs. Examples include calculating aggregate statistics, creating time-series data, or generating summary reports.
Strategies for Ensuring Data Compatibility with the Cloud Platform
Ensuring data compatibility with the cloud platform requires careful planning and execution. Several strategies contribute to successful data compatibility.
- Understanding Cloud Platform Requirements: Thoroughly understanding the target cloud platform’s data storage formats, database systems, data processing services, and API requirements is crucial. This includes understanding data type support, character encoding requirements, and data access patterns.
- Choosing Appropriate Transformation Tools: Selecting the right data transformation tools is essential. Many cloud providers offer native data transformation services (e.g., AWS Glue, Azure Data Factory, Google Cloud Dataflow). Alternatively, third-party tools or custom scripts may be necessary. The choice depends on the complexity of the transformation tasks, the volume of data, and the desired level of automation.
- Designing a Scalable Transformation Pipeline: The transformation pipeline should be designed to handle the petabyte-scale data volume efficiently. This often involves parallel processing, distributed computing, and optimized data access patterns. The pipeline should be scalable to accommodate future growth and changes in data requirements.
- Performing Data Validation and Testing: Implementing comprehensive data validation and testing is essential to ensure the accuracy and integrity of the transformed data. This includes validating data against predefined rules, comparing the transformed data with the source data, and performing end-to-end testing of the data pipeline.
- Monitoring and Optimization: Continuously monitoring the transformation process and optimizing performance are crucial. This includes monitoring resource utilization, identifying bottlenecks, and optimizing data transformation steps. Cloud platforms provide tools for monitoring and alerting on performance metrics.
Code Snippets Demonstrating Data Transformation
The following code snippet, using Apache Spark with Python, demonstrates a basic data transformation task. The example converts a CSV file containing customer data into a Parquet file, filtering for customers in a specific country and anonymizing their email addresses. This example is illustrative and should be adapted based on the specific needs of the migration.
from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, regexp_replace# Create a SparkSessionspark = SparkSession.builder.appName("DataTransformation").getOrCreate()# Read the CSV filedf = spark.read.csv("customer_data.csv", header=True, inferSchema=True)# Filter for customers in the USAdf_usa = df.filter(col("country") == "USA")# Anonymize email addressesdf_anonymized = df_usa.withColumn("email", regexp_replace(col("email"), r"(.*)@(.*)", "[email protected]"))# Write the transformed data to Parquetdf_anonymized.write.parquet("customer_data_transformed.parquet")# Stop the SparkSessionspark.stop()Post-Migration Activities and Optimization

Post-migration activities are critical for ensuring the successful integration of data into the cloud environment and realizing the full benefits of the migration. These activities involve validating the data, optimizing its performance, and establishing ongoing management practices. Neglecting these steps can lead to performance bottlenecks, increased costs, and potential security vulnerabilities. This section Artikels the key post-migration tasks and strategies for optimal cloud data management.
Data Validation and Verification
Thorough data validation is essential to confirm the accuracy and completeness of the migrated data. This process ensures that the data aligns with business requirements and is ready for operational use.
- Data Integrity Checks: Implement automated checks to verify data integrity. This can involve comparing checksums, hash values, and data counts between the source and target environments. For instance, calculate a SHA-256 hash for a large dataset before migration and then again after migration. Compare the hashes to confirm data integrity. A mismatch indicates data corruption or loss during the migration process.
- Functional Testing: Perform functional tests to validate data functionality. This includes running queries, generating reports, and executing business processes to ensure data is accessible and performing as expected. For example, if migrating a customer database, run queries to retrieve customer records, verify order history, and confirm data consistency across different tables.
- User Acceptance Testing (UAT): Involve end-users in the UAT process. Provide them with access to the migrated data and allow them to perform tasks relevant to their roles. Their feedback is crucial for identifying any discrepancies or issues with the data. For instance, allow sales representatives to access and verify customer information within the CRM system after migration.
- Data Reconciliation: Compare data sets from the source and target systems to identify any inconsistencies or missing data. Use reconciliation reports to track and resolve discrepancies. For example, compare the total number of transactions in the source and target databases. If there is a difference, investigate the cause and reconcile the data.
Performance Optimization
Optimizing data performance in the cloud involves fine-tuning data storage, access patterns, and query execution to ensure efficient data retrieval and processing.
- Data Tiering: Implement data tiering strategies to store data based on its access frequency. Frequently accessed data should reside on high-performance storage tiers, while less frequently accessed data can be moved to lower-cost storage tiers. For example, use SSD-based storage for frequently accessed database tables and object storage for archived data.
- Indexing and Query Optimization: Optimize database indexes and queries to improve data retrieval speed. Analyze query execution plans and identify bottlenecks. For instance, create indexes on frequently queried columns to speed up data retrieval. Re-write inefficient queries to reduce execution time.
- Caching: Implement caching mechanisms to store frequently accessed data in memory. This reduces the need to retrieve data from slower storage tiers. For example, use a caching service like Redis or Memcached to cache frequently accessed data from a database.
- Data Compression: Compress data to reduce storage costs and improve data transfer speeds. Use compression algorithms like GZIP or Snappy to compress data files. For instance, compress large log files before storing them in object storage to reduce storage costs.
- Partitioning: Partition large datasets to improve query performance and manageability. Partition data based on relevant criteria such as time or region. For example, partition a large time-series dataset by month to improve query performance for monthly reports.
Cost Efficiency Strategies
Optimizing costs in the cloud requires careful consideration of storage, compute, and data transfer expenses. Implement strategies to minimize these costs without sacrificing performance.
- Right-Sizing Resources: Select the appropriate size and type of cloud resources to match workload requirements. Avoid over-provisioning resources, which can lead to unnecessary costs. For example, monitor CPU and memory utilization of virtual machines and adjust the instance size accordingly.
- Storage Optimization: Choose the appropriate storage class based on data access patterns and retention requirements. Use lifecycle policies to automatically move data between different storage classes. For instance, use a cold storage class for infrequently accessed data to reduce storage costs.
- Reserved Instances and Savings Plans: Leverage reserved instances and savings plans to obtain discounts on compute and storage resources. Commit to a specific level of resource usage for a defined period to reduce costs. For example, purchase a one-year or three-year reserved instance for a virtual machine that runs consistently.
- Data Transfer Optimization: Minimize data transfer costs by optimizing data transfer methods and using data compression. For example, use a data transfer service like AWS DataSync to transfer large datasets to the cloud. Compress data before transferring it to reduce transfer costs.
- Monitoring and Budgeting: Implement robust monitoring and budgeting tools to track cloud spending and identify cost optimization opportunities. Set up alerts to notify when spending exceeds a defined threshold. For example, use AWS Cost Explorer to monitor cloud spending and set up budgets to control costs.
Ongoing Data Management Best Practices
Implementing ongoing data management practices ensures data quality, security, and compliance over time.
- Data Governance: Establish data governance policies and procedures to define data ownership, data quality standards, and data access controls. This ensures that data is managed consistently across the organization. For example, define data ownership for critical data assets and establish data quality rules to ensure data accuracy.
- Data Security: Implement robust security measures to protect data from unauthorized access and cyber threats. This includes data encryption, access controls, and regular security audits. For instance, encrypt data at rest and in transit, and implement multi-factor authentication for user access.
- Data Backup and Recovery: Implement a comprehensive backup and recovery strategy to protect against data loss. Regularly back up data and test the recovery process. For example, use cloud-native backup services to back up data and test the recovery process on a regular basis.
- Monitoring and Alerting: Implement monitoring and alerting to detect and respond to data-related issues. Monitor data storage, performance, and security metrics. For instance, monitor storage capacity and set up alerts to notify when capacity is nearing its limit.
- Change Management: Establish a change management process to manage changes to data and infrastructure. Document all changes and perform thorough testing before implementing them. For example, document all changes to database schemas and test the changes in a staging environment before deploying them to production.
Data Lifecycle Management Implementation
Data lifecycle management (DLM) policies automate the movement of data through different storage tiers based on its age and access patterns, optimizing both cost and performance.
- Define Data Retention Policies: Establish clear data retention policies based on business requirements, regulatory compliance, and data value. Determine how long data should be stored and when it should be archived or deleted. For example, retain financial records for seven years to comply with regulatory requirements.
- Automated Data Tiering: Implement automated data tiering policies to move data between different storage classes based on its age and access frequency. For example, move infrequently accessed data to a lower-cost storage class after a specified period.
- Archiving and Deletion: Archive data that is no longer actively used but needs to be retained for compliance or historical purposes. Delete data that is no longer needed or required by regulations. For example, archive historical log files to a cold storage tier and delete data that has exceeded its retention period.
- Compliance with Regulatory Requirements: Ensure data lifecycle management policies comply with relevant regulatory requirements such as GDPR, HIPAA, and CCPA. Implement data retention and deletion policies that meet these requirements. For instance, ensure that personal data is deleted when the retention period expires, as required by GDPR.
- Example Scenario: Consider a healthcare organization migrating patient records to the cloud. Implement a data lifecycle policy where recently accessed patient records reside on high-performance storage, older records are moved to a lower-cost archive storage after a year, and records older than seven years are deleted to comply with HIPAA regulations.
Final Summary
In conclusion, migrating petabytes of data to the cloud is a complex undertaking, but with careful planning, the right tools, and a robust strategy, it is achievable. From the initial planning stages to post-migration optimization, each step requires meticulous attention to detail. By understanding the various data transfer methods, prioritizing data security, optimizing network performance, and continuously monitoring progress, organizations can successfully transition their vast datasets to the cloud.
The successful migration of petabyte-scale data unlocks opportunities for enhanced data accessibility, improved scalability, and reduced operational costs, ultimately driving innovation and business growth. The implementation of data lifecycle management policies further ensures the long-term efficiency and cost-effectiveness of cloud data storage and retrieval.
FAQ Overview
What are the primary drivers for migrating petabyte-scale data to the cloud?
The key drivers include scalability, cost optimization, enhanced data accessibility, improved data security, disaster recovery capabilities, and the ability to leverage advanced cloud services like analytics and machine learning.
How does one estimate the total cost of a petabyte data migration?
Cost estimation involves factoring in data transfer fees, storage costs, compute resources for transformation, potential network optimization expenses, and the ongoing costs of cloud services post-migration. Using cloud provider pricing calculators and analyzing historical data transfer rates is recommended.
What are the critical considerations for data governance during cloud migration?
Data governance involves ensuring data quality, compliance with regulatory requirements, access control, and data lineage tracking. Establishing clear policies, implementing robust security measures, and employing data cataloging tools are crucial.
How can downtime be minimized during a petabyte data migration?
Minimizing downtime involves employing strategies such as parallel data transfer, using staged migrations, and conducting thorough testing before the final cutover. Selecting transfer methods with minimal disruption and planning for rollback scenarios are also essential.
What are the key performance indicators (KPIs) to monitor during a petabyte data migration?
Key KPIs include data transfer speed, error rates, data integrity checks, network latency, and resource utilization. Monitoring these metrics provides insights into the migration progress and helps identify potential bottlenecks or issues.